---
title: "Shared Nothing Architecture"
subtitle: "or, Writing This App Was Easier Than Cloning Myself"
description: Comprehensive Overview of a Shared Nothing Application Deployed on Fly.io
cover: dancing-clones-cover.webp
thumbnail: dancing-clones-thumb.webp
artist: Annie Ruygt
artist_link: https://annieruygtillustration.com/
alt: A number of couples dancing, including a two clones dancing with separate partners.
layout: docs
nav: guides
redirect_from: "/blog/shared-nothing/"
date: 2024-03-05
author: rubys
---
<figure>
<img src="/blog/2024-03-05/dancing-clones-cover_sm.webp" alt="Illustration by Annie Ruygt of a number of couples dancing, including a two clones dancing with separate partners." class="w-full max-w-lg mx-auto">
</figure>
<center><iframe width="600" height="315" src="https://www.youtube-nocookie.com/embed/_cT4Unk5RiU" title="YouTube video player" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share" referrerpolicy="strict-origin-when-cross-origin" allowfullscreen></iframe></center><br />
<div class="callout">
This guide from Rails and JS expert Sam Ruby is based on his personal capacity as a ballroom dance nerd. It covers how a serverful, stateful, shared-nothing architecture hit the spot for him when it came time to scale to multiple customers in different parts of the world.
</div>
## Introduction
Once upon a time, I found myself double booked at a ballroom dance competition. Read that [story in more detail on my blog](http://intertwingly.net/blog/2022/08/13/Unretiring), but essentially: you’re only supposed to get one shot to dance in a given heat, and I ended up listed twice in the spreadsheet for that heat. I decided to write an app to take the load of manual entry and scheduling off of organizers, and so that no one would ever be asked to do something impossible and be at two places at one time.
Showcase (that’s what I called it) started out as a Ruby on Rails app and a database; it kept track of competitors and their schedules for a single Showcase (that’s what these ballroom dance events are called). I ran it on a single Mac Mini in my home.
Over time, it grew out of my attic and onto VMs in the cloud. It supports more events in different cities, and does more things. Conventional wisdom is that as you grow, you make each type of service reusable and put it into a separate set of machines.
If this approach isn’t the best one for your app, throw it out the window! I did. In my case, it made a lot of sense to put all the services into a single VM, and scale out by repeating that set into new VMs. This works great for me. Maybe it’s right for your app, too! Maybe not! Prepare to bathe in the gory details of my stateful, serverful, shared-nothing monolith.
## Shared-nothing architecures
<p class="callout">
A shared-nothing architecture is a distributed computing architecture in which each update request is satisfied by a single node (processor/memory/storage unit) in a computer cluster.
</p>
As you might expect, a Showcase competition happens live and in a single location. Very few people need access to the system, and they’re often all in the same room; picture a few judges entering scores at the end of a number—that’s your peak simultaneous users. Data’s not shared between events–they don’t want or need to share a database and Redis cache.
Shared-nothing architectures are nothing new. An excerpt from [Wikipedia](https://en.wikipedia.org/wiki/Shared-nothing_architecture):
> The intent is to eliminate contention among nodes. Nodes do not share (independently access) the same memory or storage. One alternative architecture is shared everything, in which requests are satisfied by arbitrary combinations of nodes. This may introduce contention, as multiple nodes may seek to update the same data at the same time.
While serverless is one kind of a shared-nothing architecture - this post explores another variation. One where servers are explicitly deployed,
users are assigned to servers, and users have databases that aren't shared.
This application started, like most applications, small. And that's where the story begins.
## A single event
<p class="callout">
A Fly.io machine is not merely a Docker container, but rather a [full VM](https://fly.io/blog/docker-without-docker/). Treat it as such: run as many services as you like on a single machine.
</p>
My first showcase was in Harrisburg, Pennsylvania. The app I developed initially supported only that one event, and all of the services needed to support the event ran on a single machine. Like most Rails applications,
this consisted of a Rails application, a database, and (eventually) Redis. Over time a number of supporting services were added (NGINX, opensshd, rsyncd, and a small log "heartbeat" script).
Today, these all happily run on a single Fly.io machine.
Conventional wisdom is that as you grow you put each type of service into a separate set of machines. That isn't always the right approach.
An excerpt from DHH's [Majestic Monolith](https://signalvnoise.com/svn3/the-majestic-monolith/):
> Every time you extract a collaboration between objects to a collaboration between systems, you’re accepting a world of hurt with a myriad of liabilities and failure states. What to do when services are down, how to migrate in concert, and all the pain of running many services in the first place.
Another way to look at this is: as needs grow, do you really want to share a database and Redis instances between customers? (Or, in this case, between events?)
If "no" turns out to be a viable answer: go with it. Put all of the services needed to support one customer in one Docker image and then repeat that set as often
as needed. Eliminating the need for a network in producing a response to a request both increases throughput and reliability.
There are a lot of [options for running multiple processes inside a Fly.io App](https://fly.io/docs/app-guides/multiple-processes/).
I use a combination of [ENTRYPOINT](https://github.com/rubys/showcase/blob/main/bin/docker-entrypoint) running a
[deploy](https://github.com/rubys/showcase/blob/main/bin/deploy) script and a [procfile](https://github.com/rubys/showcase/blob/main/Procfile.fly).
Given the load for each event is only for one customer, I only need 1 CPU per server. While CPU is not a concern, it still is important to size
the amount of RAM needed.
Even with all of the services running, according to [Graftana/Fly Metrics](https://fly-metrics.net/), each instance uses about 220MB of RAM when idle,
and grows to 450MB when active. That being said, I have seen machines fail due to [OOM](https://en.wikipedia.org/wiki/Out_of_memory) with only 512MB, so I give
each machine 1GB. I also define an additional 2G of [swap](https://fly.io/docs/reference/configuration/#swap_size_mb-option) as
I would rather the machine run slower under peak load than crash.
Finally, invest the time to set up a [WireGuard network](https://fly.io/docs/networking/private-networking/) that lets you VPN into your own private network of machines.
## Multi-tenancy
<p class="callout">
The code base supports only a single event. Running multiple events on a single machine is the next step before jumping into multiple machines.
</p>
There are a number of blog posts out there on how to do
[multi-tenancy](https://blog.arkency.com/comparison-of-approaches-to-multitenancy-in-rails-apps/)
with Rails. [Phusion Passenger](https://www.phusionpassenger.com/) provides a [different
approach](https://stackoverflow.com/questions/48669947/multitenancy-passenger-rails-multiple-apps-different-versions-same-domain).
For this use case, the Phusion Passenger approach is the best match. The
database for a mid-size local event is about a megabyte in size (about the size
of a single camera image), and can be kept in SQLite. Passenger provides a
[`passenger_min_instances`](https://www.phusionpassenger.com/library/config/nginx/reference/#passenger_min_instances)
`0` option that allow a reasonable number of past, present, and future events
to be hosted essentially without any overhead when not in use. This does mean
that you have to accept the cold start times of the first access, but that
appears to be two seconds or less on modern hardware, which is acceptable.
The NGINX configuration file defines a set of environment variables for each tenant to control
the name of such things as the database, the log file, base URL, and pidfile.
For web sockets (Action Cable), NGINX is [preferred over Apache
httpd](https://www.phusionpassenger.com/library/config/apache/action_cable_integration/).
The [documentation for Deploying multiple apps on a single server
(multitenancy)](https://www.phusionpassenger.com/library/deploy/nginx/) is
still listed as todo, but the following is what I have been able to figure out:
- One action cable process is allocated per server (i.e., listen port).
- In order to share the action cable process, all apps on the same server will
need to share the same Redis URL and channel prefix. The [Rails
documentation](https://guides.rubyonrails.org/action_cable_overview.html#redis-adapter)
suggests that you use a different channel prefix for different applications
on the same server -- **IGNORE THAT**.
- Instead, use environment variables to stream from, and broadcast to, different
action cable channels.
The end result is what outwardly appears to be a single Rails app, with a
single set of assets and a single cable. One additional rails instance
serves the index and provides a global administration interface.
Recapping: a single server can host multiple events, each event is a separate instance of the same Rails application with a separate SQLite database placed on a volume. The server is always on (`auto_stop_machines = false`), but the Rails apps are spun up when needed and spin down when idle (using [`passenger_pool_idle_time`](https://www.phusionpassenger.com/library/config/nginx/reference/#passenger_pool_idle_time))
## Multiple regions
<p class="callout">
Distributing an app across multiple regions not only lets you service requests close
to your users, it enables horizontal scalability and isolation.
</p>
While most of my users are US based, my showcase app now has a second user in Australia, and now one in Warsaw, Poland.
Sending requests and replies half way around the world unnecessarily adds latency.
As each machine is monolithic and self-contained, replicating service into a new region is
a matter of creating the new machine and routing requests to the correct machine.
This application use three separate techniques to route requests.
The first technique is to [listen](https://github.com/rubys/showcase/blob/main/app/javascript/controllers/region_controller.js) for
[turbo:before-fetch-requests](https://turbo.hotwired.dev/reference/events#http-requests) events and
insert a [fly-prefer-region header](https://fly.io/docs/networking/dynamic-request-routing/#the-fly-prefer-region-request-header).
The region is extracted from a data attribute added to the [body](https://github.com/rubys/showcase/blob/aae08a6d57f92335b2cdbb94756e5416b7b50f83/app/views/layouts/application.html.erb#L16) tag.
This all made possible by how [Turbo works](https://turbo.hotwired.dev/handbook/introduction#turbo-drive%3A-navigate-within-a-persistent-process):
> This happens by intercepting all clicks on `<a href>` links to the same domain. When you click an eligible link, Turbo Drive prevents the browser from following it, changes the browser’s URL using the History API, requests the new page using fetch, and then renders the HTML response.
The same source above also defines a `window.inject_region` function to inject the header in other places in the code that may issue fetch requests.
The next (and final) two approaches are done in the NGINX configuration itself. This configuration is defined at startup on
each machine. Here is an example of the definition for `raleigh` on machines in regions other than `iad`:
```
## Raleigh
location /showcase/2024/raleigh/cable {
add_header Fly-Replay region=iad;
return 307;
}
location /showcase/2024/raleigh {
proxy_set_header X-Forwarded-Host $host;
proxy_pass http://iad.smooth.internal:3000/showcase/2024/raleigh;
}
```
This replays action cable (web socket) requests to the correct region, and
[reverse proxies](https://docs.nginx.com/nginx/admin-guide/web-server/reverse-proxy/)
all other requests to the correct machine using its [`.internal` address](https://fly.io/docs/networking/private-networking/#fly-io-internal-addresses). The latter is done because [fly-replay](https://fly.io/docs/networking/dynamic-request-routing/#limitations)
is limited to 1MB requests, and uploading audio files may exceed this limit.
## Appliances
<p class="callout">
For larger tasks, try
decomposing parts of your applications into event handlers, starting up Machines to handle requests when needed, and stopping them when the requests are done.
</p>
While above I've sung the praises of a Majestic Monolith, there are limits. Usage of this application
is largely split into two phases: a lengthy period of data entry, followed by a brief period of report generation.
This pattern then repeats a second time as scores are entered and then distributed.
Report generation is done using [puppeteer](https://pptr.dev/) and [Google Chrome](https://www.google.com/chrome/).
While this app runs comfortably with 1MB of RAM, I've had Google Chrome crash machines that have 2MB.
Generating a PDF from a web page (including authentication) is something that can be run independently of
all of the other services of your application. By making use of [`auto_stop_machines` and `auto_start_machines`](https://fly.io/docs/reference/configuration/#the-http_service-section),
a machine dedicated to this task can be spun up in seconds and perform this function.
In my case, no changes to the application itself is needed, just a few lines of NGINX configuration:
```
## PDF generation
location ~ /showcase/.+\.pdf$ {
add_header Fly-Replay app=smooth-pdf;
return 307;
}
```
This was originally published as [Print on Demand](https://fly.io/blog/print-on-demand/),
and the code for that article can be found on [GitHub as fly-apps/pdf-appliance](https://github.com/fly-apps/pdf-appliance).
This architectural pattern can be applied whenever there is a minority of requests that require an outsized amount
of resources. A second example that comes to mind: I've had requests for audio capture and transcription.
Setting up a machine that [runs Whisper with Fly GPUs](https://news.ycombinator.com/item?id=39417197) is
something I plan to explore.
## Backups
<p class="callout">
Running databases on a single volume attached to a single machine is a single
point of failure. It is imperative that you have recent backups in case of failure.
</p>
At this point, databases are small, and can be moved between servers with a simple configuration change.
For that reason, for the moment I've elected to have each machine contain a complete copy of all of the databases.
To make that work, I
[install](https://github.com/rubys/showcase/blob/aae08a6d57f92335b2cdbb94756e5416b7b50f83/Dockerfile#L67),
[configure](https://github.com/rubys/showcase/blob/main/Dockerfile#L114-L137), and
[start](https://github.com/rubys/showcase/blob/aae08a6d57f92335b2cdbb94756e5416b7b50f83/bin/deploy#L26-L27)
[rsync](https://rsync.samba.org/).
With Passenger, I set [`passenger_min_instances`](https://www.phusionpassenger.com/library/config/nginx/reference/#passenger_max_pool_size) to zero, allowing
each application to completely shutdown after five minutes of inactivity. I define a
[`detached_process`](https://www.phusionpassenger.com/library/indepth/hooks.html#detached_process) hook to run
a [script](https://github.com/rubys/showcase/blob/main/bin/passenger-hook).
As that hook will be run after each process exits, what it does first is query the number of running processes. If
there are none (not counting websockets), it begins the backup to each Fly.io machine
using `rsync --update` to only replace the newer files. After that completes, a webhook
is run on an offsite machine (a mac mini in my attic) to rsync all files there. In order for that to work, I run
[an ssh server](https://fly.io/docs/app-guides/opensshd/) on each Fly.io machine.
And I don't stop there:
* My home machine runs the same passenger application configured to serve all of the events.
This can be used as a hot backup. I've never needed it, but it comforting to have.
* I also rsync all of the data to a [Hetzner](https://www.hetzner.com/) which
runs the same application.
* Finally, I have a cron job on my home machine that makes a daily backup of all of the databases. A new directory
is created per day, and [hard links](https://en.wikipedia.org/wiki/Hard_link) are used to link to the same file
in the all too common case where a database hasn't changed during the course of the day. As this is in a terabyte
drive, I haven't bothered to prune, so at this point, I have daily backups going back years.
While this may seem like massive overkill, always having a local copy of all of the databases to use to reproduce problems
and test fixes, as well as having a complete instance that I can effectively use as a staging server alone makes all this
worth it.
Finally, since each region contains a copy of all databases, I use [`auto_extend_size_threshold`](https://fly.io/docs/reference/configuration/#auto_extend_size_threshold) and
[`auto_extend_size_increment`](https://fly.io/docs/reference/configuration/#auto_extend_size_increment) to ensure that I never run out of space.
## Logging
<p class="callout">
It is important that logs are there when you need them. For this reason, logs need both monitoring and redundancy.
</p>
Equally as important as backups are logs. Over the course of the life of this application I've had two cases where
I've lost data due to errors on my part and was able to reconstruct that data by re-applying POST requests extracted
from logs.
The biggest problem with logs is that you take them for granted. You see that they work and forget about them, and
there always is the possibility that they are not working when you need them.
I've written about my approach in [Multiple Logs for Resiliency](https://fly.io/blog/redundant-logs/), but a summary here:
* Since I have volumes already, I [instruct Rails to broadcast logs there](https://github.com/rubys/showcase/blob/aae08a6d57f92335b2cdbb94756e5416b7b50f83/config/environments/production.rb#L102-L110) in addition to stdout.
The API to do this changed in Rails 7.1, and the code I linked to does this both ways. This data isn't replicated to other volumes and
only contains Rails logs, as it really is only intended for when all else fails.
* I have a [logger](https://github.com/rubys/showcase/tree/main/fly/applications/logger) app that I run in two regions.
This writes log entries to volumes, and runs a small web server that I can use to browse and navigate the log entries.
This data too is backed up (forever) to my home server, and is only kept for seven days on the log server.
Two major additions since I wrote up that blog entry:
* I have each machine [create a heartbeat log entry every 30 minutes](https://github.com/rubys/showcase/blob/main/bin/log-heartbeat.sh), and each log server runs a
[monitor](https://github.com/rubys/showcase/blob/main/fly/applications/logger/monitor.ts) once an hour to
ensure that every machine has checked in. If a machine doesn't check in, a [Sentry](https://sentry.io/)
alert is generated.
* I have my log tracker query Sentry whenever I visit the web page to see if there are new events. This
serves as an additional reminder to go check for errors.
I strongly encourage people to look into [Sentry](https://community.fly.io/t/integrated-sentry-error-tracking/15278).
## Applying updates
<p class="callout">
While Fly.io will start machines fast, you have to do your part.
If your app doesn't start fast, start something else that starts quickly first
so your users see something while they are waiting.
</p>
If you go to https://smooth.fly.dev/ the server nearest to you will need to spin up the index application. And if, from there, you click on demo, a second application will be started. While you might get lucky and somebody else (or a bot) may have already started these for you, the normal case is that you will have to wait.
Since all the services that are needed to support this application are on one machine, `fly deploy` can't simply start a new machine, wait for it to start, direct traffic to it, and only then start dismantling the previous machine. Instead, each machine needs to be taken offline, have the rootfs replaced with a new image, and all of its services restarted. Once that is complete, migrations need to be run on that machine; and in my case I may have several SQLite databases that need to be upgraded. I also have each machine that comes up rsync with the primary region. And finally, I generate an operational NGINX configuration and run [nginx reload](https://docs.nginx.com/nginx/admin-guide/basic-functionality/runtime-control/).
While this overall process may take some time, NGINX starts fast so I start it first with a [configuration](https://github.com/rubys/showcase/blob/main/config/nginx.startup) that directs everything to a [Installing updates..](http://smooth.fly.dev/showcase/503.html) page that auto refreshes every 15 seconds which normally is ample time for all this to occur. Worst case, this page simply refreshes again until the server is ready.
Even with this in place, it still is worthwhile to make the application boot fast. Measuring the times of the various components of startup, in my case Rails startup time dominates, and it turns out that effectively `bin/rails db:prepare` starts Rails once for each database.
I found that I can avoid that by [getting a list of migrations](https://github.com/rubys/showcase/blob/cb3a05fd48c22a140effcf03ccfa9bd038a0df30/config/tenant/nginx-config.rb#L186),
and then [comparing that list to the list of migrations already deployed](https://github.com/rubys/showcase/blob/cb3a05fd48c22a140effcf03ccfa9bd038a0df30/config/tenant/nginx-config.rb#L207-L215).
I also moved preparation of my demo database to [build time](https://github.com/rubys/showcase/blob/cb3a05fd48c22a140effcf03ccfa9bd038a0df30/Dockerfile#L139-L140). In most cases, this means that my users
see no down time at all, just an approximately two second delay on their next request as Rails restarts.
## Administration
<p class="callout">
While Fly.io provides a [Machines API](https://fly.io/docs/machines/working-with-machines/),
you can go a long way with old-fashioned scripting using the [flyctl](https://fly.io/docs/flyctl/)
command.
</p>
Now lets look at what happens when I create a new event, in a new region. I (a human) get an email, I bring up my admin UI (on an instance of the index app I mentioned above). I fill out a form for the new event. I go to a separate page and add a new region. I then go to a third form where I can review and apply the changes. This involves regenerating my map, and I need to update the NGINX configuration in every existing region. There are shortcuts I can utilize which will update files on each machine and reload the NGINX configuration, but I went that way I would need to ensure that the end result exactly matches the reproducible result that a subsequent `fly deploy` would produce. I don't need that headache, so I'm actually using `fly deploy` which can add tens of seconds to the actual deploy time.
I started out running the various commands manually, but that grew old fast. So eventually
I invested in creating an admin UI.
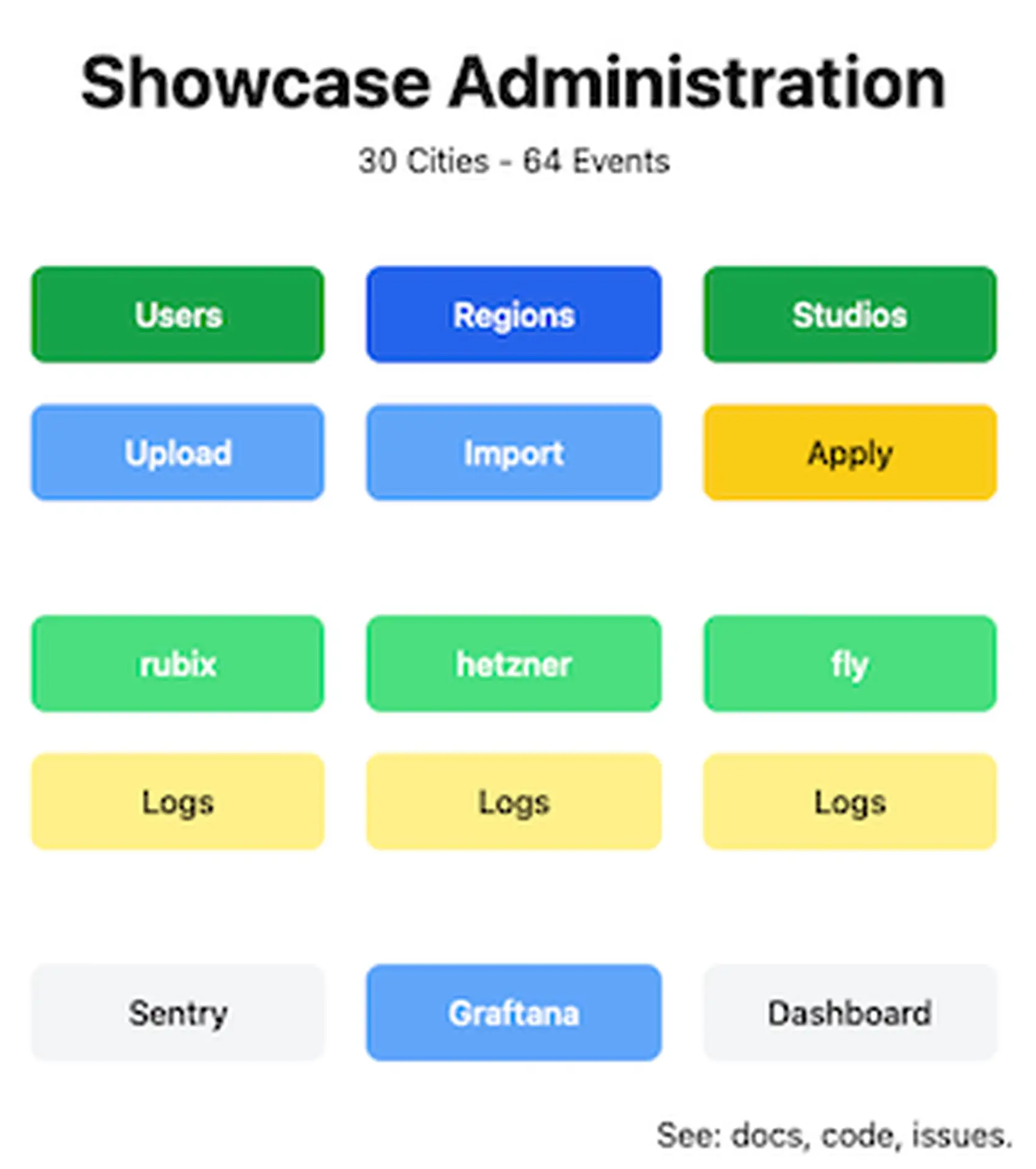
Here's what the front page of the admin UI looks like:
<img alt="Showcase Administration" src="/blog/shared-nothing/assets/adminui-cover.webp" style="width: 50vw; margin-left: 5vw">
From there, I can add, remove, and reconfigure my events, and apply changes. I can also visit
this app on three different servers, and see the logs from each. Finally, I have links to handy
tools. The Sentry link that is current gray turns red when there are new events.
I'm actually very happy with the result. The fact that I could get an email and add an event and have everything up and running on a server half a world away in less than five minutes is frankly amazing to me.
And to be honest, most of that is waiting on the human (me), followed by the amount of time it takes to build and deploy a
new image in nine regions.
And in most cases, I can now make and deploy changes from my smartphone rather than requiring
my laptop.
For those who are curious, here's the [deployment script](https://github.com/rubys/showcase/blob/main/bin/apply-changes.rb).
## Costs
<p class="callout">
This is a decent sized personal project, deployed across three continents. Even with a
significant amount of over-provisioning, the costs per month are around $60, before taking
into account plans and allowances.
</p>
I'm currently running this app in nine regions. I have two machine running a log server.
I have two machines that will run puppeteer and Chrome on demand.
[Fly.io pricing](https://fly.io/docs/about/pricing/) includes a number of plans which include a number of allowances. To
keep things simple, I'm going to ignore all of that and just look at the total costs.
From there, add your plan and subtract your allowances to see what this would cost for you.
And be aware that things may change, the below numbers are current as of early March, 2024.
Let's start with compute. 9 shared-cpu-1x machines with 1GB each at $5.70 per month total $51.30.
Two shared-cpu-1x machines with 512MB each at $3.19 per month total $6.38.
The print on demand machines are on bigger machines, but are only run when requested.
I've configured them to stay up for 15 minutes when summoned. Despite all of this the
costs for a typical month are around $0.03. So we are up to $57.71.
Next up volumes. I have 9 machines with 3GB disks, and 2 machines that only need 1G each.
29GB at $0.15 per month is $1.35.
I have a dedicated IPv4 address in order to use ssh. This adds $2.00 per month.
Outbound transfer is well under the free allowance, but for completeness I'm seeing about 16GB in North America and Europe,
which at $0.02 per GB amounts to $0.32. And about 0.1GB in Asia Pacific, which at $0.04 per GB adds less than a cent,
but to be generous, let's accept a total of $0.33.
Adding up everything, this would be 57.71 + 1.35 + 2.00 + 0.33 for a total of $61.39 per month.
Again, this is before factoring in plans and allowances, and reflects the current pricing in March of 2023.
For my needs to date, I'm clearly over-provisioning, but it is nice to have a picture of what
a fully fleshed out system would cost per month to operate.
## Summary
<p class="callout">
Shared Nothing architectures are a great way to scale up applications where the data involved is easily partitionable.
</p>
Key points (none of these should be a surprise, they were highlighted
in the text above):
* Run as many services as you like on a single machine; this both increases throughput and reliability.
* You can even run multiple instances of the same app on a machine.
* Distributing your apps across multiple regions lets you service requests close to your users.
* For larger tasks, start up machines on demand.
* Every backup plan should have a backup plan.
* Not only should you have logs, logs should be monitored and have redundancy.
* Make sure that you start something quickly -- even if it is only a "please wait" placeholder -- to make sure that your app is always servicing requests.
* Create an administration UI and write scripts you can use to change your configuration.
And finally, this app currently supports 77 events in 36 cities with 9 servers for less than you probably pay for a dinner out a month or a smart phone plan.
## Background
<p class="callout">
Feel free to skip or skim this section. It describes how the application came to be, what it does, and a high level description of its usage needs.
</p>
Background information on how this application came to be, and got me involved with Fly.io can be found
at [Unretiring](http://intertwingly.net/blog/2022/08/13/Unretiring) on my personal blog.
Here's an excerpt from that post:
> I was at a local ballroom dance competition and found myself listed twice in one heat - a scheduling mishap where I was expected to be on the floor twice with two different dance partners.
>
> After the event, Carolyn and I discovered that the organizers used a spreadsheet to collect entries and schedule heats. A very manual and labor prone process, made more difficult by the need to react to last minute cancellations due to the ongoing pandemic.
>
> Carolyn told the organizers that I could do better, and volunteered me to write a program. I thought it would be fun so I agreed.
This application is [on GitHub](https://github.com/rubys/showcase#readme), and while each individual event requires authentication for access, a full function demo can be accessed at [https://smooth.fly.dev/](ht
tp://smooth.fly.dev/). It was originally deployed a single Mac mini, and now is running on a small fleet of machines in the Fly.io network.
---
Couples ballroom dance competitions are called a "Showcase".
The application supports:
- managing all the contestants
- storing and playing dance music for solos
- invoicing students and studios
- managing the schedule
- printing heat sheets, back numbers, and labels
- recording the judges' scores
- publishing results
As you might expect, a Showcase competition happens live and in one location. There are very few users who need access to the system and they often are all physically in the same location.
Here we'll cover how a Ruby on Rails application using a SQLite database can be deployed to the nearest Fly.io region for the event and how elegantly it solved this problem, including the ability to easily deploy new servers from the application.
---
The core Showcase application is implemented on top of Ruby on Rails, augmented by two separate services implemented in JavaScript an run using [Bun](https://bun.sh/). While the details may vary, many of the core principles described below apply to other applications,
even applications using other frameworks. In fact, many of the pieces of advice provided below apply to apps you host yourself, or host on
other cloud providers.
But first, some useful approximations that characterize this app, many of which will guide the choice of architecture:
* Each event is a separate instance of the Rails application, with a its own separate database.
* A typical database is one megabyte. Not a typo: one megabyte. Essentially, the app is a spreadsheet with a [Turbo](https://turbo.hotwired.dev/handbook/introduction) web front end.
* All the services needed to support an event are run on a single VM.
* Persistence consists of the database, storage (used for uploaded audio files), and logs.
* Typical response time for a request is 100ms or less.
* Peak transaction per second per database is approximately 1. Again, not a typo -- think spreadsheet.
* Peak number of simultaneous users is often one, but even when there are multiple they tend to be all in the same geographic region, often in the same room (example: multiple judges entering scores).
* Transactions are generally a blend of reads and writes with neither dominating.
This lends itself well to horizontal scaling, where every event effectively has a dedicated VM. Again, this is a useful approximation - as not every event is "active", multiple events can share a VM. As needs change, databases can be moved to different VMs.
## Related reading
- [Getting Started with N‑Tier Architecture](/docs/blueprints/n-tier-architecture/) A contrasting architecture pattern where state is shared across the data tier — useful for understanding when shared‑nothing *isn’t* the best fit.
- [Session Affinity (a.k.a. Sticky Sessions)](/docs/blueprints/sticky-sessions/) Focused on routing and state‑isolation patterns that often come up when you adopt a shared‑nothing approach and need to keep state local to a machine.
- [Networking](/docs/networking/) The comprehensive networking overview (private networks, Anycast, WireGuard tunnels, routing) — helpful when building globally distributed isolated nodes in a shared‐nothing architecture.
Shared Nothing Architecture
This guide from Rails and JS expert Sam Ruby is based on his personal capacity as a ballroom dance nerd. It covers how a serverful, stateful, shared-nothing architecture hit the spot for him when it came time to scale to multiple customers in different parts of the world.
Introduction
Once upon a time, I found myself double booked at a ballroom dance competition. Read that story in more detail on my blog, but essentially: you’re only supposed to get one shot to dance in a given heat, and I ended up listed twice in the spreadsheet for that heat. I decided to write an app to take the load of manual entry and scheduling off of organizers, and so that no one would ever be asked to do something impossible and be at two places at one time.
Showcase (that’s what I called it) started out as a Ruby on Rails app and a database; it kept track of competitors and their schedules for a single Showcase (that’s what these ballroom dance events are called). I ran it on a single Mac Mini in my home.
Over time, it grew out of my attic and onto VMs in the cloud. It supports more events in different cities, and does more things. Conventional wisdom is that as you grow, you make each type of service reusable and put it into a separate set of machines.
If this approach isn’t the best one for your app, throw it out the window! I did. In my case, it made a lot of sense to put all the services into a single VM, and scale out by repeating that set into new VMs. This works great for me. Maybe it’s right for your app, too! Maybe not! Prepare to bathe in the gory details of my stateful, serverful, shared-nothing monolith.
Shared-nothing architecures
A shared-nothing architecture is a distributed computing architecture in which each update request is satisfied by a single node (processor/memory/storage unit) in a computer cluster.
As you might expect, a Showcase competition happens live and in a single location. Very few people need access to the system, and they’re often all in the same room; picture a few judges entering scores at the end of a number—that’s your peak simultaneous users. Data’s not shared between events–they don’t want or need to share a database and Redis cache.
Shared-nothing architectures are nothing new. An excerpt from Wikipedia:
The intent is to eliminate contention among nodes. Nodes do not share (independently access) the same memory or storage. One alternative architecture is shared everything, in which requests are satisfied by arbitrary combinations of nodes. This may introduce contention, as multiple nodes may seek to update the same data at the same time.
While serverless is one kind of a shared-nothing architecture - this post explores another variation. One where servers are explicitly deployed,
users are assigned to servers, and users have databases that aren’t shared.
This application started, like most applications, small. And that’s where the story begins.
A single event
A Fly.io machine is not merely a Docker container, but rather a full VM. Treat it as such: run as many services as you like on a single machine.
My first showcase was in Harrisburg, Pennsylvania. The app I developed initially supported only that one event, and all of the services needed to support the event ran on a single machine. Like most Rails applications,
this consisted of a Rails application, a database, and (eventually) Redis. Over time a number of supporting services were added (NGINX, opensshd, rsyncd, and a small log “heartbeat” script).
Today, these all happily run on a single Fly.io machine.
Conventional wisdom is that as you grow you put each type of service into a separate set of machines. That isn’t always the right approach.
Every time you extract a collaboration between objects to a collaboration between systems, you’re accepting a world of hurt with a myriad of liabilities and failure states. What to do when services are down, how to migrate in concert, and all the pain of running many services in the first place.
Another way to look at this is: as needs grow, do you really want to share a database and Redis instances between customers? (Or, in this case, between events?)
If “no” turns out to be a viable answer: go with it. Put all of the services needed to support one customer in one Docker image and then repeat that set as often
as needed. Eliminating the need for a network in producing a response to a request both increases throughput and reliability.
Given the load for each event is only for one customer, I only need 1 CPU per server. While CPU is not a concern, it still is important to size
the amount of RAM needed.
Even with all of the services running, according to Graftana/Fly Metrics, each instance uses about 220MB of RAM when idle,
and grows to 450MB when active. That being said, I have seen machines fail due to OOM with only 512MB, so I give
each machine 1GB. I also define an additional 2G of swap as
I would rather the machine run slower under peak load than crash.
Finally, invest the time to set up a WireGuard network that lets you VPN into your own private network of machines.
Multi-tenancy
The code base supports only a single event. Running multiple events on a single machine is the next step before jumping into multiple machines.
For this use case, the Phusion Passenger approach is the best match. The
database for a mid-size local event is about a megabyte in size (about the size
of a single camera image), and can be kept in SQLite. Passenger provides a
passenger_min_instances0 option that allow a reasonable number of past, present, and future events
to be hosted essentially without any overhead when not in use. This does mean
that you have to accept the cold start times of the first access, but that
appears to be two seconds or less on modern hardware, which is acceptable.
The NGINX configuration file defines a set of environment variables for each tenant to control
the name of such things as the database, the log file, base URL, and pidfile.
One action cable process is allocated per server (i.e., listen port).
In order to share the action cable process, all apps on the same server will
need to share the same Redis URL and channel prefix. The Rails
documentation
suggests that you use a different channel prefix for different applications
on the same server – IGNORE THAT.
Instead, use environment variables to stream from, and broadcast to, different
action cable channels.
The end result is what outwardly appears to be a single Rails app, with a
single set of assets and a single cable. One additional rails instance
serves the index and provides a global administration interface.
Recapping: a single server can host multiple events, each event is a separate instance of the same Rails application with a separate SQLite database placed on a volume. The server is always on (auto_stop_machines = false), but the Rails apps are spun up when needed and spin down when idle (using passenger_pool_idle_time)
Multiple regions
Distributing an app across multiple regions not only lets you service requests close
to your users, it enables horizontal scalability and isolation.
While most of my users are US based, my showcase app now has a second user in Australia, and now one in Warsaw, Poland.
Sending requests and replies half way around the world unnecessarily adds latency.
As each machine is monolithic and self-contained, replicating service into a new region is
a matter of creating the new machine and routing requests to the correct machine.
This application use three separate techniques to route requests.
This happens by intercepting all clicks on <a href> links to the same domain. When you click an eligible link, Turbo Drive prevents the browser from following it, changes the browser’s URL using the History API, requests the new page using fetch, and then renders the HTML response.
The same source above also defines a window.inject_region function to inject the header in other places in the code that may issue fetch requests.
The next (and final) two approaches are done in the NGINX configuration itself. This configuration is defined at startup on
each machine. Here is an example of the definition for raleigh on machines in regions other than iad:
This replays action cable (web socket) requests to the correct region, and
reverse proxies
all other requests to the correct machine using its .internal address. The latter is done because fly-replay
is limited to 1MB requests, and uploading audio files may exceed this limit.
Appliances
For larger tasks, try
decomposing parts of your applications into event handlers, starting up Machines to handle requests when needed, and stopping them when the requests are done.
While above I’ve sung the praises of a Majestic Monolith, there are limits. Usage of this application
is largely split into two phases: a lengthy period of data entry, followed by a brief period of report generation.
This pattern then repeats a second time as scores are entered and then distributed.
Report generation is done using puppeteer and Google Chrome.
While this app runs comfortably with 1MB of RAM, I’ve had Google Chrome crash machines that have 2MB.
Generating a PDF from a web page (including authentication) is something that can be run independently of
all of the other services of your application. By making use of auto_stop_machines and auto_start_machines,
a machine dedicated to this task can be spun up in seconds and perform this function.
In my case, no changes to the application itself is needed, just a few lines of NGINX configuration:
This architectural pattern can be applied whenever there is a minority of requests that require an outsized amount
of resources. A second example that comes to mind: I’ve had requests for audio capture and transcription.
Setting up a machine that runs Whisper with Fly GPUs is
something I plan to explore.
Backups
Running databases on a single volume attached to a single machine is a single
point of failure. It is imperative that you have recent backups in case of failure.
At this point, databases are small, and can be moved between servers with a simple configuration change.
For that reason, for the moment I’ve elected to have each machine contain a complete copy of all of the databases.
With Passenger, I set passenger_min_instances to zero, allowing
each application to completely shutdown after five minutes of inactivity. I define a
detached_process hook to run
a script.
As that hook will be run after each process exits, what it does first is query the number of running processes. If
there are none (not counting websockets), it begins the backup to each Fly.io machine
using rsync --update to only replace the newer files. After that completes, a webhook
is run on an offsite machine (a mac mini in my attic) to rsync all files there. In order for that to work, I run
an ssh server on each Fly.io machine.
And I don’t stop there:
My home machine runs the same passenger application configured to serve all of the events.
This can be used as a hot backup. I’ve never needed it, but it comforting to have.
I also rsync all of the data to a Hetzner which
runs the same application.
Finally, I have a cron job on my home machine that makes a daily backup of all of the databases. A new directory
is created per day, and hard links are used to link to the same file
in the all too common case where a database hasn’t changed during the course of the day. As this is in a terabyte
drive, I haven’t bothered to prune, so at this point, I have daily backups going back years.
While this may seem like massive overkill, always having a local copy of all of the databases to use to reproduce problems
and test fixes, as well as having a complete instance that I can effectively use as a staging server alone makes all this
worth it.
It is important that logs are there when you need them. For this reason, logs need both monitoring and redundancy.
Equally as important as backups are logs. Over the course of the life of this application I’ve had two cases where
I’ve lost data due to errors on my part and was able to reconstruct that data by re-applying POST requests extracted
from logs.
The biggest problem with logs is that you take them for granted. You see that they work and forget about them, and
there always is the possibility that they are not working when you need them.
Since I have volumes already, I instruct Rails to broadcast logs there in addition to stdout.
The API to do this changed in Rails 7.1, and the code I linked to does this both ways. This data isn’t replicated to other volumes and
only contains Rails logs, as it really is only intended for when all else fails.
I have a logger app that I run in two regions.
This writes log entries to volumes, and runs a small web server that I can use to browse and navigate the log entries.
This data too is backed up (forever) to my home server, and is only kept for seven days on the log server.
Two major additions since I wrote up that blog entry:
I have my log tracker query Sentry whenever I visit the web page to see if there are new events. This
serves as an additional reminder to go check for errors.
While Fly.io will start machines fast, you have to do your part.
If your app doesn’t start fast, start something else that starts quickly first
so your users see something while they are waiting.
If you go to https://smooth.fly.dev/ the server nearest to you will need to spin up the index application. And if, from there, you click on demo, a second application will be started. While you might get lucky and somebody else (or a bot) may have already started these for you, the normal case is that you will have to wait.
Since all the services that are needed to support this application are on one machine, fly deploy can’t simply start a new machine, wait for it to start, direct traffic to it, and only then start dismantling the previous machine. Instead, each machine needs to be taken offline, have the rootfs replaced with a new image, and all of its services restarted. Once that is complete, migrations need to be run on that machine; and in my case I may have several SQLite databases that need to be upgraded. I also have each machine that comes up rsync with the primary region. And finally, I generate an operational NGINX configuration and run nginx reload.
While this overall process may take some time, NGINX starts fast so I start it first with a configuration that directs everything to a Installing updates.. page that auto refreshes every 15 seconds which normally is ample time for all this to occur. Worst case, this page simply refreshes again until the server is ready.
Even with this in place, it still is worthwhile to make the application boot fast. Measuring the times of the various components of startup, in my case Rails startup time dominates, and it turns out that effectively bin/rails db:prepare starts Rails once for each database.
I found that I can avoid that by getting a list of migrations,
and then comparing that list to the list of migrations already deployed.
I also moved preparation of my demo database to build time. In most cases, this means that my users
see no down time at all, just an approximately two second delay on their next request as Rails restarts.
Administration
While Fly.io provides a Machines API,
you can go a long way with old-fashioned scripting using the flyctl
command.
Now lets look at what happens when I create a new event, in a new region. I (a human) get an email, I bring up my admin UI (on an instance of the index app I mentioned above). I fill out a form for the new event. I go to a separate page and add a new region. I then go to a third form where I can review and apply the changes. This involves regenerating my map, and I need to update the NGINX configuration in every existing region. There are shortcuts I can utilize which will update files on each machine and reload the NGINX configuration, but I went that way I would need to ensure that the end result exactly matches the reproducible result that a subsequent fly deploy would produce. I don’t need that headache, so I’m actually using fly deploy which can add tens of seconds to the actual deploy time.
I started out running the various commands manually, but that grew old fast. So eventually
I invested in creating an admin UI.
Here’s what the front page of the admin UI looks like:
From there, I can add, remove, and reconfigure my events, and apply changes. I can also visit
this app on three different servers, and see the logs from each. Finally, I have links to handy
tools. The Sentry link that is current gray turns red when there are new events.
I’m actually very happy with the result. The fact that I could get an email and add an event and have everything up and running on a server half a world away in less than five minutes is frankly amazing to me.
And to be honest, most of that is waiting on the human (me), followed by the amount of time it takes to build and deploy a
new image in nine regions.
And in most cases, I can now make and deploy changes from my smartphone rather than requiring
my laptop.
This is a decent sized personal project, deployed across three continents. Even with a
significant amount of over-provisioning, the costs per month are around $60, before taking
into account plans and allowances.
I’m currently running this app in nine regions. I have two machine running a log server.
I have two machines that will run puppeteer and Chrome on demand.
Fly.io pricing includes a number of plans which include a number of allowances. To
keep things simple, I’m going to ignore all of that and just look at the total costs.
From there, add your plan and subtract your allowances to see what this would cost for you.
And be aware that things may change, the below numbers are current as of early March, 2024.
Let’s start with compute. 9 shared-cpu-1x machines with 1GB each at $5.70 per month total $51.30.
Two shared-cpu-1x machines with 512MB each at $3.19 per month total $6.38.
The print on demand machines are on bigger machines, but are only run when requested.
I’ve configured them to stay up for 15 minutes when summoned. Despite all of this the
costs for a typical month are around $0.03. So we are up to $57.71.
Next up volumes. I have 9 machines with 3GB disks, and 2 machines that only need 1G each.
29GB at $0.15 per month is $1.35.
I have a dedicated IPv4 address in order to use ssh. This adds $2.00 per month.
Outbound transfer is well under the free allowance, but for completeness I’m seeing about 16GB in North America and Europe,
which at $0.02 per GB amounts to $0.32. And about 0.1GB in Asia Pacific, which at $0.04 per GB adds less than a cent,
but to be generous, let’s accept a total of $0.33.
Adding up everything, this would be 57.71 + 1.35 + 2.00 + 0.33 for a total of $61.39 per month.
Again, this is before factoring in plans and allowances, and reflects the current pricing in March of 2023.
For my needs to date, I’m clearly over-provisioning, but it is nice to have a picture of what
a fully fleshed out system would cost per month to operate.
Summary
Shared Nothing architectures are a great way to scale up applications where the data involved is easily partitionable.
Key points (none of these should be a surprise, they were highlighted
in the text above):
Run as many services as you like on a single machine; this both increases throughput and reliability.
You can even run multiple instances of the same app on a machine.
Distributing your apps across multiple regions lets you service requests close to your users.
For larger tasks, start up machines on demand.
Every backup plan should have a backup plan.
Not only should you have logs, logs should be monitored and have redundancy.
Make sure that you start something quickly – even if it is only a “please wait” placeholder – to make sure that your app is always servicing requests.
Create an administration UI and write scripts you can use to change your configuration.
And finally, this app currently supports 77 events in 36 cities with 9 servers for less than you probably pay for a dinner out a month or a smart phone plan.
Background
Feel free to skip or skim this section. It describes how the application came to be, what it does, and a high level description of its usage needs.
Background information on how this application came to be, and got me involved with Fly.io can be found
at Unretiring on my personal blog.
Here’s an excerpt from that post:
I was at a local ballroom dance competition and found myself listed twice in one heat - a scheduling mishap where I was expected to be on the floor twice with two different dance partners.
After the event, Carolyn and I discovered that the organizers used a spreadsheet to collect entries and schedule heats. A very manual and labor prone process, made more difficult by the need to react to last minute cancellations due to the ongoing pandemic.
Carolyn told the organizers that I could do better, and volunteered me to write a program. I thought it would be fun so I agreed.
This application is on GitHub, and while each individual event requires authentication for access, a full function demo can be accessed at https://smooth.fly.dev/. It was originally deployed a single Mac mini, and now is running on a small fleet of machines in the Fly.io network.
Couples ballroom dance competitions are called a “Showcase”.
The application supports:
managing all the contestants
storing and playing dance music for solos
invoicing students and studios
managing the schedule
printing heat sheets, back numbers, and labels
recording the judges’ scores
publishing results
As you might expect, a Showcase competition happens live and in one location. There are very few users who need access to the system and they often are all physically in the same location.
Here we’ll cover how a Ruby on Rails application using a SQLite database can be deployed to the nearest Fly.io region for the event and how elegantly it solved this problem, including the ability to easily deploy new servers from the application.
The core Showcase application is implemented on top of Ruby on Rails, augmented by two separate services implemented in JavaScript an run using Bun. While the details may vary, many of the core principles described below apply to other applications,
even applications using other frameworks. In fact, many of the pieces of advice provided below apply to apps you host yourself, or host on
other cloud providers.
But first, some useful approximations that characterize this app, many of which will guide the choice of architecture:
Each event is a separate instance of the Rails application, with a its own separate database.
A typical database is one megabyte. Not a typo: one megabyte. Essentially, the app is a spreadsheet with a Turbo web front end.
All the services needed to support an event are run on a single VM.
Persistence consists of the database, storage (used for uploaded audio files), and logs.
Typical response time for a request is 100ms or less.
Peak transaction per second per database is approximately 1. Again, not a typo – think spreadsheet.
Peak number of simultaneous users is often one, but even when there are multiple they tend to be all in the same geographic region, often in the same room (example: multiple judges entering scores).
Transactions are generally a blend of reads and writes with neither dominating.
This lends itself well to horizontal scaling, where every event effectively has a dedicated VM. Again, this is a useful approximation - as not every event is “active”, multiple events can share a VM. As needs change, databases can be moved to different VMs.
Related reading
Getting Started with N‑Tier Architecture A contrasting architecture pattern where state is shared across the data tier — useful for understanding when shared‑nothing isn’t the best fit.
Session Affinity (a.k.a. Sticky Sessions) Focused on routing and state‑isolation patterns that often come up when you adopt a shared‑nothing approach and need to keep state local to a machine.
Networking The comprehensive networking overview (private networks, Anycast, WireGuard tunnels, routing) — helpful when building globally distributed isolated nodes in a shared‐nothing architecture.