

Fly.io runs apps (globally) in just few commands. That means a lot of log output! Centralizing logs is important. Fire up an app and follow along as we see just how easy it can be.
Nearly all of our apps are puking output. Sometimes, it’s intentional. Often this output is in the form of structured logs.
Logs are helpful for a variety of use cases - debugging, tracking, collating, correlating, coalescing, and condensing the happenings of your code into useful bits of human-parsable information.
There can be a lot of logs, from a lot of apps. Aggregating logs to a central place is useful for many reasons, but here are my top 2 favorite:
- Correlation - Being able to search/query/report on all your logs in one place helps you correlate events (“Joe deleted prod again”) amongst services
- Retention - Fly.io doesn’t keep your logs around forever. If you want to see them, retain them!
The Logging River
Since we grab stdout from the processes run in your apps, whatever an app outputs becomes a log. Logs are constantly flowing through Fly.io’s infrastructure.
Image: Wikimedia
{kind=link}

Here’s how that works.
Your apps run in a VM via Firecracker. Inside the VM, we inject an init process (pid 1) that runs and monitors your app. Since we build VM’s from Docker images, init is taking ENTRYPOINT + CMD and running that.
The init program (really just a bit of Rust that we named init) is, among other things, gathering process output from stdout and shooting it into a socket.
Outside of the VM, on the host, a bit of Golang takes that output and sends it to Vector via yet-another socket.
Vector’s job is to ship logs to other places. In this case, those logs (your app’s output) are shipped to an internal NATS cluster. For the sake of simplicity, let’s call NATS a “fancy, clustered pubsub service”. Clients can subscribe to specific topics, and NATS sends the requested data to those subscribers.
In true Fly.io fashion, a proxy sits in front of NATS. We call this proxy “Flaps” (Fly Log Access Pipeline Server™, as one does). Flaps ensures you only see your own logs.
NATS is the fun part! You can hook into NATS (via Flaps) to get your logs.
To get your logs, all you need is an app that acts as a NATS client, reads the logs, and ships them somewhere. Vector can do just that! It’s fairly simple - in fact, we’ve done the work for you:
The Fly Log Shipper™
To ship your logs, you can run an instance of the Fly Log Shipper.
This app configures a Vector sink of your choosing, and runs Vector. A sink is a “driver” that Vector will ship logs to, for example Loki, Datadog, or (bless your heart) Cloudwatch.
I liked the look of Logtail, so I tried out its free tier.
Logtail actually lets you set Fly.io as a source of logs, but as we can see, we’re actually just telling Vector to send logs somewhere. If your log aggregator doesn’t know Fly.io exists, that’s fine. It just needs a Vector sink to exist. The process is the same no matter what log aggregator you use.
If you sign up for Logtail, it helpfully gives you instructions on setting that up with Fly.io.
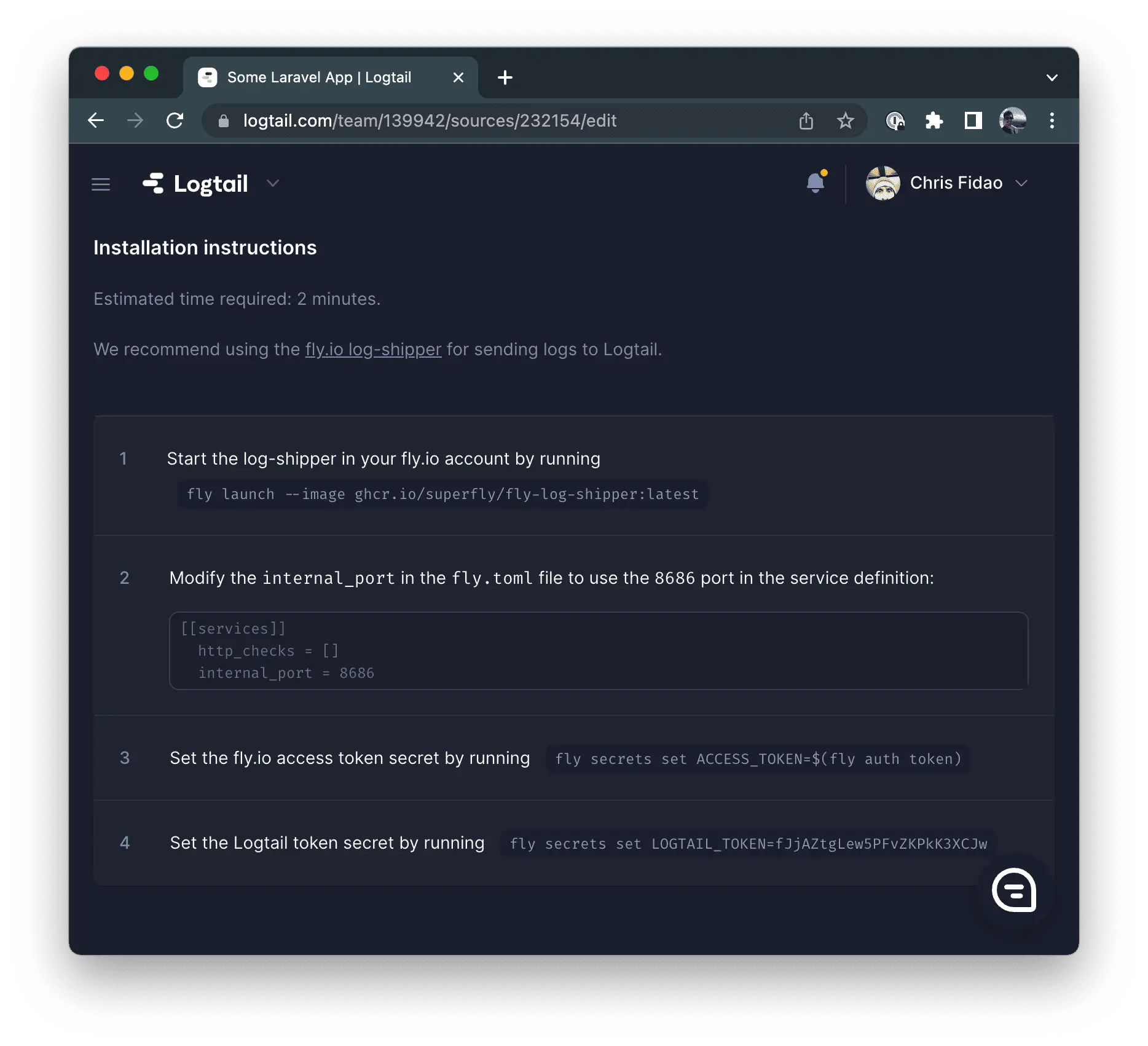
Let’s go ahead and follow those instructions (they’re similar to what you see on the Log Shipper repo).
Using the Log Shipper
The NATS log stream is scoped to your organization. This means that the Fly Log Shipper collects logs from all your applications.
Here’s how to set it up with Logtail:
# Make a directory for
# our log shipper app
mkdir logshippper
cd logshippper
# I chose not to deploy yet
fly launch --image ghcr.io/superfly/fly-log-shipper:latest
# Set some secrets. The secret / env var you set
# determines which "sinks" are configured
fly secrets set ORG=personal
fly secrets set ACCESS_TOKEN=$(fly auth token)
fly secrets set LOGTAIL_TOKEN=<token provided by logtail source>
You can configure as many providers as you’d like by adding more secrets. The secrets needed are determined by which provider(s) you want to use.
Before launching your application, you should edit the generated fly.toml file and delete the entire [[services]] section. Replace it with this:
[[services]]
http_checks = []
internal_port = 8686
Then you can deploy it:
fly deploy
You’ll soon start to see logs appear from all of your apps.
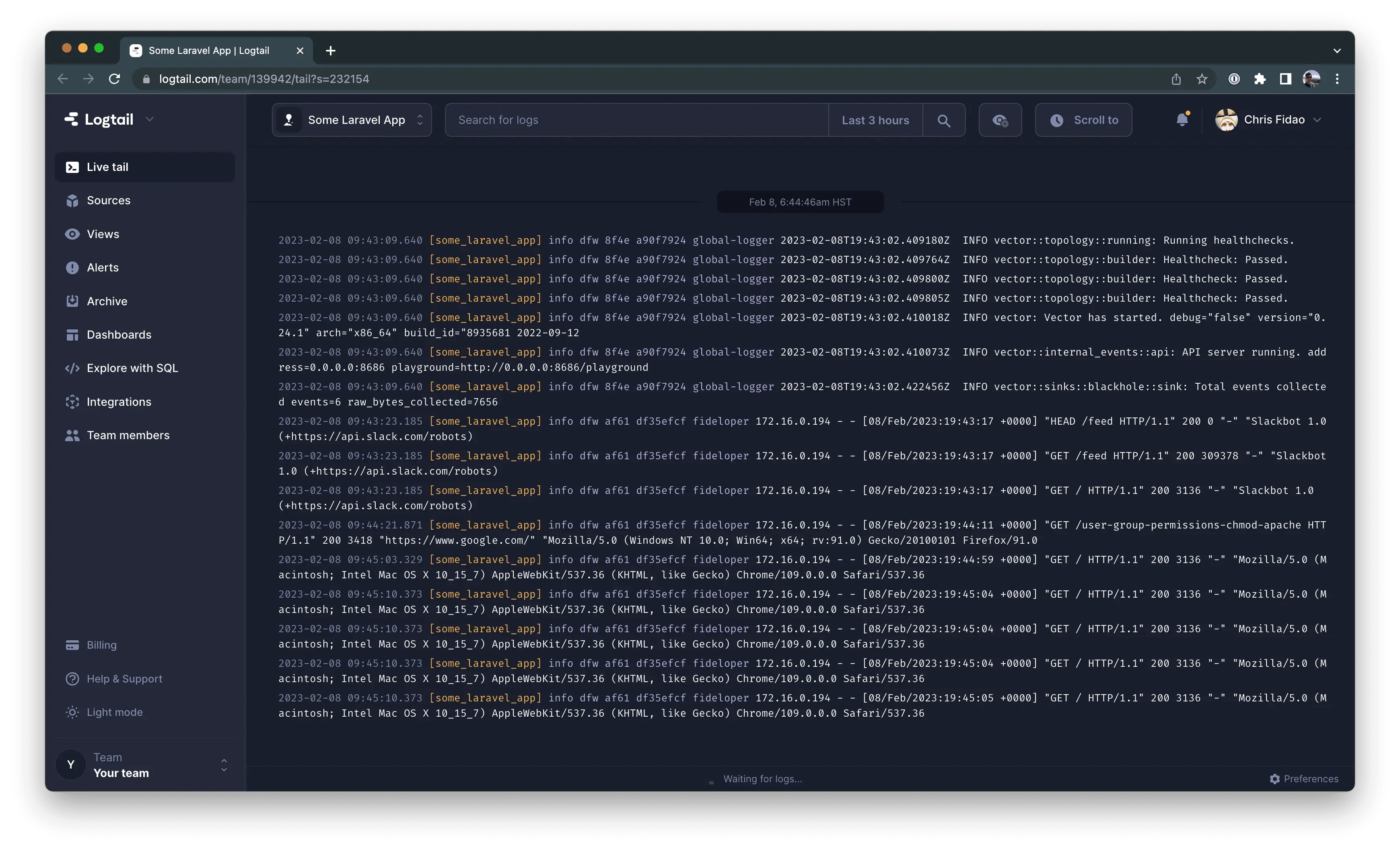
That wasn’t too bad!
Try it out yourself!
You have apps. Apps have logs! Run your apps and ship your logs in just a few commands.
Deploy your app! →
Shipping Specific Logs
So far we’ve seen how to ship logs from every application in your organization.
You can, however, narrow that down by setting a SUBJECT environment variable. That can be set in the fly.toml‘s [env] section, or as an application secret.
I opted to add it to my fly.toml, which looked like this:
[env]
SUBJECT = "logs.sandwich.>"
The subject is in format logs.<app_name>.<region>.<instance_id>. An example SUBJECT to only log an application named sandwich (no matter what region it’s in) is:
SUBJECT="logs.sandwich.>"
See that greater-than symbol >? That’s a NATS wildcard. There are also regular wildcards *, but the special wildcard > is used at the end of the string to say “and anything to the right of this”.
So, our use of "logs.sandwich.>" says to ship any logs that are from application sandwich, no matter what region or instance they come from. You can (ab)use this to get the logs you’re interested in.
Go forth and ship logs!