

We’re Fly.io, a global sandwich-rating company with a hosting problem. Even if you don’t have a sandwich to rate, you might benefit from the hosting platform we built. Check it out: with a working Docker image, you can be up and running on Fly.io in just minutes.
So, you want to build an app to rate sandwiches. Well, the world has a lot of different sandwiches. Pit beefs in Baltimore, Tonkatsu sandos in Shinjuku, and Cemitas in Puebla. You want real-time sandwich telemetry, no matter the longitude of the sandwich. So you need to run it all over the world, without a lot of ceremony.
We built one of those at Fly.io. We’ve written a bunch about one important piece of the puzzle: how we take Docker images from our users and efficiently run them as virtual machines. You can run a Docker image as VM. You’re almost done! Time to draw the rest of the owl.
To turn our Docker transmogrification into a platform, we need to go from running a single job to running hundreds of thousands. That’s an engineering problem with a name:
Orchestration
Orchestrators link clusters of worker servers together and offer up an API to run jobs on them. Kubernetes is an orchestrator; the Kleenex of orchestrators. Then, HashiCorp has Nomad, which we use, and about which more in a bit.
Find a serverside developer complaining about how much harder it is to deliver an app in 2023 than it was in 2005, and odds are, they’re complaining about orchestration. They’re not wrong: Kubernetes is fractally complicated. But the idea isn’t.
Let’s write an orchestrator. Start by writing a supervisor.
for _, task := range tasks {
wg.Add(1)
go func(t Task) {
defer wg.Done()
argv := strings.Split(t.Command, " ")
for {
cmd := exec.Command(argv[0], argv[1:]...)
cmd.Start()
cmd.Wait()
if !t.Restart {
break
}
}
}(task)
}
wg.Wait()
I believe this design is so powerful it does not need to be discussed.
A build-your-own-light-saber tool if ever there was one.
There are, like, 100 different supervisors. You can write a program to run a shell command, you can write a supervisor. Come on. You’ve already written a supervisor. Let’s stop kidding each other.
Let’s turn ours into an orchestrator.
For illustrative purposes, our supervisor takes a JSON configuration:
[
{
"Name": "frick",
"Command": "sleep 1",
"Restart": true
},
{
"Name": "frack",
"Command": "sleep 5"
}
]
Instead of reading this configuration from a file, like a dumb old supervisor, read it from an HTTP API, like a majestic orchestrator. “Workers” run our simple supervisor code, and a server doles out tasks. Here’s an API:
GET /sched/jobs # polled
POST /sched/claim/{name}
POST /sched/release/{name}
GET /sched/cancellations # polled
POST /sched/submit
GET /sched/status/{name}
POST /sched/cancel/{name}
The server implementing this is an exercise for the reader. Don’t overthink it .
Workers poll /jobs. They /claim them by name. The server decides which claim wins, awarding it a 200 HTTP response. The worker runs the job, until it stops, and posts /release.
End-users drive the orchestrator with the same API; they post JSON tasks to /submit, check to see where they’re running, kill them by name with /cancel. Workers poll /cancellations to see what to stop running.
There. That’s an orchestrator. It’s just a client-server process supervisor.
I see a lot of hands raised in the audience. I’ll take questions at the end. But let’s see if I can head some of them off:
- Sure, it’s unusual for an orchestrator to run shell commands. A serious orchestrator would run Docker containers (or some agglomeration of multiple Dockerfiles called a Pod or a Brood or a Murder). But that’s just a detail; a constant factor of new lines calling the containerd SDK. Knock yourself out!
- Yeah, if you were running this in some big enterprise, you’d need some kind of security and access control; this thing is just
rsh. These are just details. - “That’s a stupid API” isn’t a question.
- No, I don’t know what should happen if the server goes down. Something sane. Cancel and restart all the tasks.
- OK, having all the workers stampeding to grab conflicting jobs is inefficient. But at most cluster sizes, who cares? Have the workers wait a random interval before claiming. Have them randomize the job they try to claim. It’ll probably scale fine.
- Yes, you could just do this with Redis and
BLPOP.
You there in the back hollering… this isn’t a real orchestrator, why? Oh, because we’re not
Scheduling
Scheduling means deciding which worker to run each task on.
Scheduling is to an orchestrator what a routing protocol is to a router: the dilithium crystal, the contents of Marcellus Wallace’s briefcase, the thing that, ostensibly, makes the system Difficult.
It doesn’t have to be hard. Assume our cluster is an undifferentiated mass of identical workers on the same network. Decide how many jobs a worker can run. Then: just tell a worker not to bid on jobs when it’s at its limit.
But no mainstream orchestrator works this way. All of them share some notion of centralized scheduling: an all-seeing eye that allocates space on workers the way a memory allocator doles out memory.
Even centralized scheduling doesn’t complicate our API that much.
POST /sched/register # {'cpu':64,'mem':256,'diskfree':'4t'}
GET /sched/assigned
POST /sched/started/{name}
POST /sched/stopped/{name}
GET /sched/cancellations
Instead of rattling off all the available jobs and having workers stampede to claim them, our new API assigns them directly. Easier for the workers, harder for the server, which is now obligated to make decisions.
Here’s the rough outline of a centralized scheduler:
- Filter out workers that fail to match constraints, like sufficient disk space or CPUs or microlattice shapecasters.
- Rank the surviving workers.
The textbook way to rank viable workers is “bin packing”. Bin packing is a classic computer science problem: given a series of variably-sized objects and fixed-size containers, fit all the objects in the smallest number of containers. The conventional wisdom about allocating jobs in a cluster is indeed that of the clown car: try to make servers as utilized as possible, so you can minimize the number of servers you need to buy.
So far, the mechanics of what I’m describing are barely an afternoon coding project. But real clusters tend to run Kubernetes. Even small clusters: people run K8s for apps like ratemysandwich.com all the time. But K8s was designed to host things like all of Google. So K8s has fussy scheduling system.
To qualify as “fussy”, a scheduler needs at least 2 of the following 3 properties:
- Place jobs on workers according to some optimum that is theoretically NP-hard to obtain (but is in practice like 2 nested
forloops). - Accounting for varying resource requirements for jobs using a live inventory of all the workers and something approximating a constraint solver.
- Scaling to huge clusters, without a single point of failure, so that the scheduler itself becomes a large distributed system.
These tenets of fussiness hold true not just for K8s, but for all mainstream orchestrators, including the one we use.
Nomad
Let’s start by reckoning with what’s going on with Kubernetes.
The legends speak of a mighty orchestrator lurking within the halls of Google called “Borg”. Those of us who’ve never worked at Google have to take the word of those who have that Borg actually exists, and the word of other people that K8s is based on the design of Borg.
The thing about Borg is that, if it exists, it exists within an ecosystem of other internal Google services. This makes sense for Google the same way having S3, SQS, ECS, Lambda, EBS, ALBs, CloudWatch, Cognito, EFS, RedShift, Route53, Glacier, SNS, VPC, Certificate Manager, QFA, IAM, KMS, CodeCommit, OpsWorks, Cloudformation, Snowball, X-Ray, Price List Marketplace Metering Service Entitlement Modernization, and EC2 does for AWS. Like, somewhere within Google there’s a team that’s using each of these kinds of service.
You can’t argue with the success Kubernetes has had. I get it.
It makes less sense for a single piece of software to try to wrap up all those services. But Kubernetes seems to be trying. Here’s some perspective: K8s is, some people say, essentially Borg but with Docker Containers instead of Midas packages. Midas is neat, but it in turn relies on BigTable and Colossus, two huge Google services. And that’s just packages, the lowest level primitive in the system. It’s an, uh, ambitious starting point for a global open source standard.
At any rate, our customers want to run Linux apps, not Kubernetes apps. So Kubernetes is out.
Sometime later, a team inside Google took it upon themselves to redesign Borg. Their system was called Omega. I don’t know if it was ever widely used, but it’s influential. Omega has these properties:
- Distributed scheduling, so that scheduling decisions could be made on servers across the cluster instead of a monolithic single central scheduler.
- A complete, up-to-date picture of available resources on the cluster (via a Paxos-replicated database) provided to all schedulers.
- Optimistic transactions: if a proposed decision fails, because it conflicts with some other claim on the same resources, your scheduler just tries again.
Hashicorp took Google’s Omega paper and turned it into an open source project, called Nomad.
Omega’s architecture is nice. But the real win is that Nomad is lightweight. It’s conceptually not all that far from the API we designed earlier, plus Raft.
Nomad can run Unix programs directly, or in Docker containers. We do neither. Not a problem: Nomad will orchestrate jobs for anything that conforms to this interface:
RecoverTask(*TaskHandle) error
StartTask(*TaskConfig) (*TaskHandle, *DriverNetwork, error)
WaitTask(ctx context.Context, taskID string) (<-chan *ExitResult, error)
StopTask(taskID string, timeout time.Duration, signal string) error
DestroyTask(taskID string, force bool) error
InspectTask(taskID string) (*TaskStatus, error)
// plus some other goo
For the year following our launch, Fly.io’s platform was a Rust proxy and a Golang Nomad driver. The driver could check out a Docker image, convert it to a block device, and start Firecracker on it. In return for coding to the driver interface, we got:
- Constraint-based deployments that let us tell a specific Fly app to run in Singapore (har cheong gai burger), Sydney (hamdog), and Frankfurt (doner kebab), on dedicated CPU instances with 2 cores and at least 4 gigs of memory, say.
- The ability to move Fly Apps around our fleet, draining them off specific machines for maintenance.
- Opt-in integration with Consul, which we used for request routing and to glue our API to our platform backend.
About Nomad itself, we have nothing but nice things to say. Nomad is like Flask to K8s’s Django, Sinatra to K8s’s Rails. It’s unopinionated, easy to set up, and straightforward to extend. Use Nomad.
Another very cool system to look at in this space is Flynn. Flynn was an open source project that started before Docker was stable and grew up alongside it. They set out to build a platform-as-a-service in a box, one that bootstraps itself from a single-binary install. It does so much stuff! If you’ve ever wondered what all the backend code for something like Fly.io must be like (multiple generations of schedulers and all), check out what they did.
But we’ve outgrown it, because:
Bin packing is wrong for platforms like Fly.io. Fussy schedulers are premised on minimizing deployed servers by making every server do more. That makes a lot of sense if you’re Pixar. We rent out server space. So we buy enough of them to have headroom in every region. As long as they’re running, we’d want to use them.
Here’s a Google presentation on the logic behind Nomad’s first-fit bin packing scheduler. It was designed for a cluster where 0% utilization was better, for power consumption reasons, than < 40% utilization. Makes sense for Google. Not so much for us.
With strict bin packing, we end up with Katamari Damacy scheduling, where a couple overworked servers in our fleet suck up all the random jobs they come into contact with. Resource tracking is imperfect and neighbors are noisy, so this is a pretty bad customer experience.
Nomad added a “spread scheduling” option, which just inverts the bin pack scoring they use by default. But that’s not necessarily what we want. What we want is complicated! We’re high-maintenance! In a geographically diverse fleet with predictable usage patterns, the best scheduling plans are intricate, and we don’t want to fight with a scheduler to implement them.
We Run One Global Cluster. This isn’t what Nomad expects. Nomad wants us to run a bunch of federated clusters (one in Dallas, one in Newark, and so on).
There are two big reasons we don’t federate Nomad:
- It changes the semantics of how apps are orchestrated, which would require fiddly engineering for us to wire back into our UX. For instance: there isn’t an obvious, clean way to roll back a failing app deploy across a dozen regions all at once. We have lots of regions, but offer one platform to our users, so we run into lots of stuff like this.
- Even if we did that work, Nomad pricing looks at us and sees Apple, Inc. More power to them! But, like, no.
We Outgrew The Orchestration Model. Nomad scheduling is asynchronous. You submit a job to a server. All the servers convene a trustees meeting, solicit public comment, agree on the previous meeting’s minutes, and reach consensus about the nature of the job requested. A plan is put into motion, and the implicated workers are informed. Probably, everything works fine; if not, the process starts over again, and again, until seconds, minutes, hours, or days later, it does work.
This is not a bad way to handle a flyctl deploy request. But it’s no way to handle an HTTP request, and that’s what we want: for a request to land at our network edge in São Paulo, and then we scale from zero to handle it in our GRU region, starting a Fly Machine on a particular server, synchronously.
The Fly.io step in there that costs the most is pulling containers from registries. People’s containers are huge! That makes the win from caching large – and just not captured by the Nomad scheduler.
Nomad autoscaling is elegant, and just not well matched to our platform. How the autoscaler works is, it takes external metrics and uses them to adjust the count constraint on jobs. We scrape metrics every 15 seconds, and then Nomad’s scheduling work adds a bunch of time on top of that, so it never really worked effectively.
At this point, what we’re asking our scheduler to do is to consider Docker images themselves to be a resource, like disk space and memory. The set of images cached and ready to deploy on any given server is changing every second, and so are the scheduling demands being submitted to the orchestrator. Crazy producers. Crazy consumers. It’s a lot to ask from a centralized scheduler.
So we built our own, called
Nümad
I would also accept “nonomad”, “yesmad”, “no, mad”, and “fauxmad” for this dad joke.
Just kidding, we call it flyd.
There is a long and distinguished literature of cluster scheduling, going back into the 1980s. We decided not to consult it, and just built something instead.
flyd has a radically different model from Kubernetes and Nomad. Mainstream orchestrators are like sophisticated memory allocators, operating from a reliable global picture of all capacity everywhere in the cluster. Not flyd.
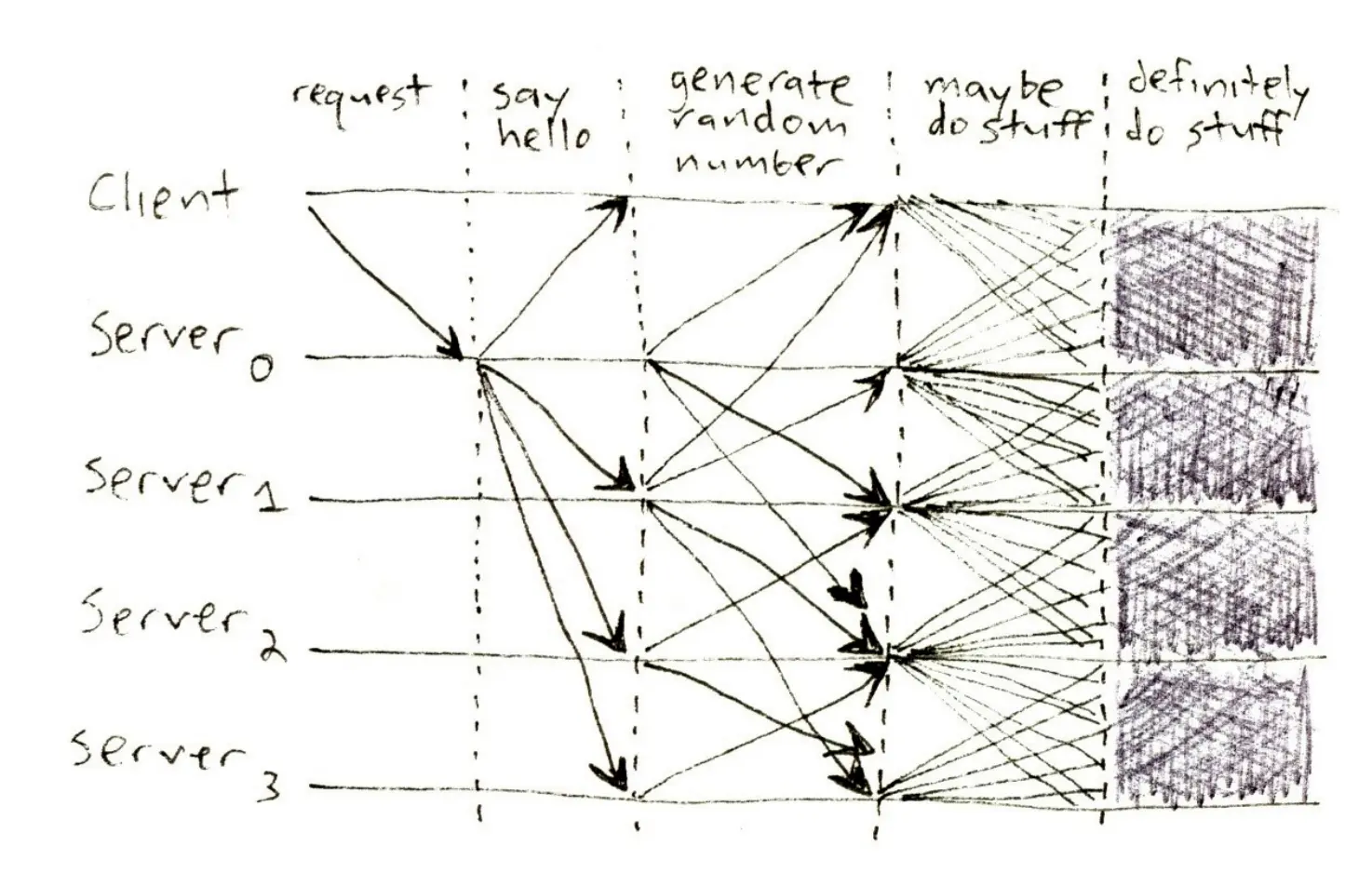
Instead, flyd operates like a market. Requests to schedule jobs are bids for resources; workers are suppliers. Our orchestrator sits in the middle like an exchange. ratemysandwich.com asks for a Fly Machine with 4 dedicated CPU cores in Chennai (sandwich: bun kebab?). Some worker in MAA offers room; a match is made, the order is filled.
Or, critically: the order is not filled. That’s fine too! What’s important is that the decision be made quickly, so that it can be done synchronously. What we don’t want is a pending state waiting for the weather to clear up.
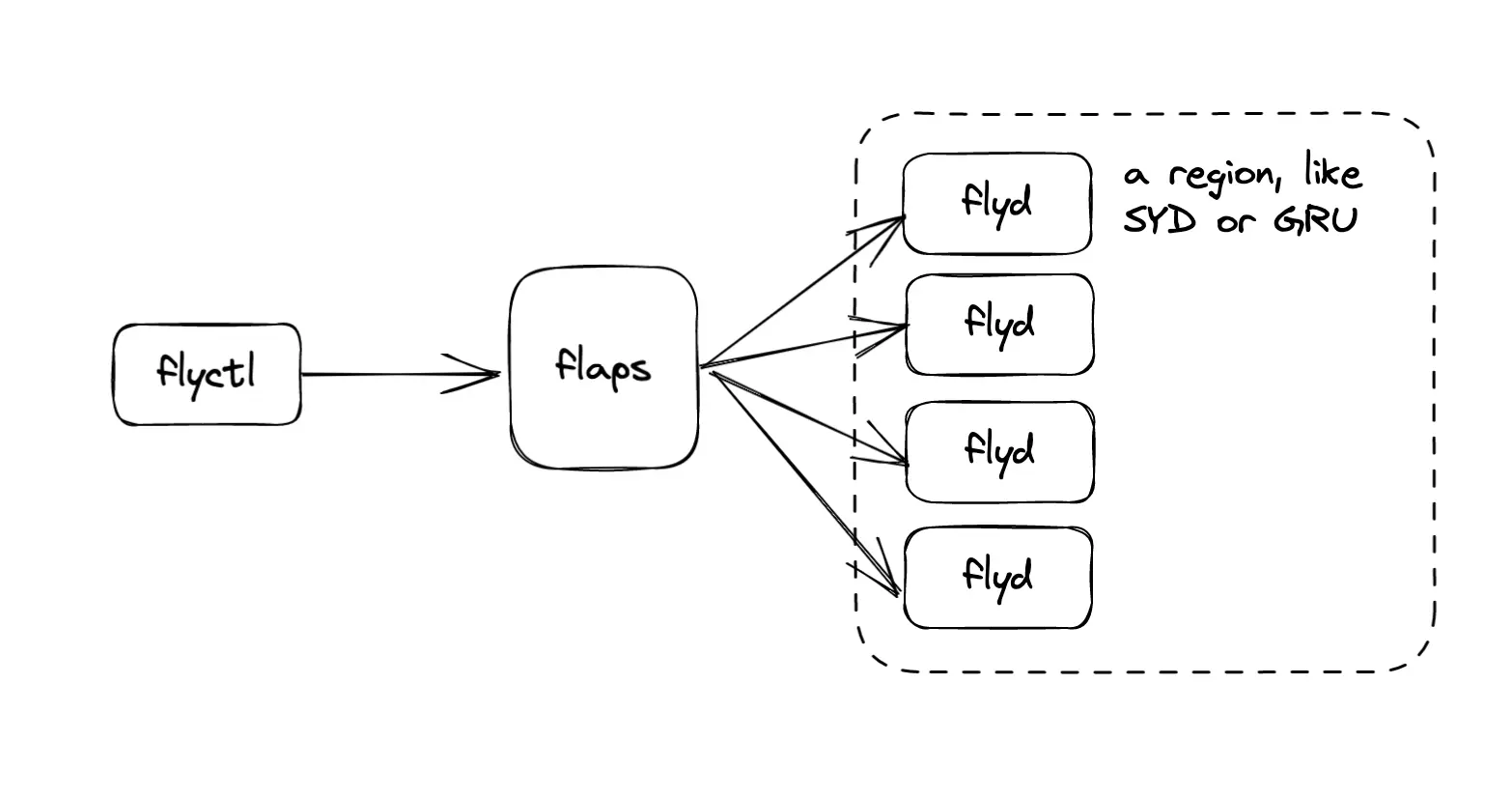
Our system has a cast of three characters:
flydis the source of truth for all the VMs running on a particular worker.flapsis a stateful proxy for all theflydinstances.flyctlis our CLI. You know it, you love it.
The engine of this system is flyd.
In Nomad-land, our Firecracker driver doesn’t keep much state. That’s the job of huge scheduling servers, operating in unlighted chambers beyond time amidst the maddening beating and monotonous whine of the Raft consensus protocol.
Unlike Nomad, which goes through some effort to keep the entire map of available resources in the cluster in memory, nothing in flyd is cached; everything is just materialized on-demand from disk.
In flyd-land, state-keeping is very much the worker’s problem. Every worker is its own source of truth. Every flyd keeps a boltdb database of its current state, which is an append-only log of all the operations applied to the worker.
flyd is rigidly structured as a collection of state machines, like “create a machine” or “delete a volume”. Each has a concrete representation both in the code (using Go generics) and in boltdb. Everything happening in flyd (in logs, traces, metrics or whatever) happens at a particular state for a particular resource ID. Easy to reason about. And, of course, if we bounce flyd, it picks up right where it left off.
flyd operates off of a local boltdb database, but our platform also has an SQLite view of all the resources allocated systemwide. We built it by caching Consul, but, in keeping with our ethos of “if you see Raft anywhere, something went wrong”, we’ve replaced it with something simpler. We call it Corrosion.
Corrosion is what would happen if you looked at Consul, realized every server is its own source of truth and thus distributed state wasn’t a consensus problem at all but rather just a replication problem, built a SWIM gossip system, and made it spit out SQLite. Also you decided it should be written in Rust. Corrosion is neat, and we’ll eventually write more about it.
All the flyd instances in (say) Madrid form a MAD cluster. But it’s not a cluster in the same sense Nomad or K8s uses: no state is shared between the flyd instances, and no consensus protocol runs.
To get jobs running on a flyd in MAD, you talk to flaps. flaps is running wherever you are (in my case, ORD).
flaps uses Corrosion to find all the workers in a particular region. It has direct connectivity to every flyd, because our network is meshed up with WireGuard. flyd exposes an internal HTTP API to flaps, and flaps in turn exposes this API:
GET /v1/apps/my-app/machines # list
POST /v1/apps/my-app/machines # create
GET /v1/apps/{machineid} # show
DELETE /v1/apps/{machineid}
POST /v1/apps/{machineid}/start
POST /v1/apps/{machineid}/stop
“Creating” a Fly Machine reserves space on a worker in some region.
 To reserve space in Sydney,
To reserve space in Sydney, flaps collects capacity information from all the flyds in SYD, and then runs a quick best-fit ranking over the workers with space, which is just a simple linear interpolation rankings workers as more or less desirable at different utilizations of different resources.
† (and, in the future, the cartesian of regions cross new hardware products, like space modulator coprocessors)
Rather than forming distributed consensus clusters, Fly.io regions like MAD and SYD† are like products listed on an exchange. There are multiple suppliers of MAD VMs (each of our workers in Madrid) and you don’t care which one you get. flaps act like a broker. Orders come in, and we attempt to match them. flaps does some lookups in the process, but it doesn’t hold on to any state; the different flaps instances around the world don’t agree on a picture of the world. The whole process can fail, the same way an immediate-or-cancel order does with a financial market order. That’s OK!
Here’s what doesn’t happen in this design: jobs don’t arrive and then sit on the book in a “pending” state while the orchestrator does its best to find some place, any place to run it. If you ask for VMs in MAD, you’re going to get VMs in MAD, or you’re going to get nothing. You won’t get VMs in FRA because the orchestrator has decided “that’s close enough”. That kind of thing happened to us all the time with Nomad.
Scheduling, Reconsidered
If you’re a certain kind of reader, you’ve noticed that this design doesn’t do everything Fly Apps do. What happens when an app crashes? How do we deploy across a bunch of regions? How does a rollback work? These are problems Nomad solved. It doesn’t look like flaps and flyd solve them.
That’s because they don’t! Other parts of the platform — most notably, flyctl, our beloved CLI — take over those responsibilities.
For example: how do we handle a crashed worker? Now, flyd will restart a crashed VM, of course; that’s an easy decision to make locally. But some problems can’t be fixed by a single worker. Well, one thing we do is: when you do a deploy, flyctl creates multiple machines for each instance. Only one is started, but others are prepped on different workers. If a worker goes down, fly-proxy notices, and sends a signal to start a spare.
What we’re doing more generally is carving complex, policy-heavy functionality out of our platform, and moving it out to the client. Aficionados of classic papers will recognize this as an old strategy.
Networks, boy I tell ya.
What we had with Nomad was a system that would make a lot of sense if we were scheduling a relatively small number of huge apps. But we schedule a huge number of relatively small apps, and the intelligent decisions our platform made in response to stimuli were often a Mad Hatter’s tea party. For instance: many times when Europe lost connectivity to us-east-1 S3, apps would flake, and Nomad would in response cry “change places!” and reschedule them onto different machines.
What we’ve concluded is that these kinds of scheduling decisions are actually the nuts and bolts of how our platform works. They’re things we should have very strong opinions about, and we shouldn’t be debating a bin packer or a constraint system to implement them. In the new design, the basic primitives are directly exposed, and we just write code to configure them the way we want.
Internally, we call this new system “AppsV2”, because we’re good at naming things. If you’re deploying an app in January of 2023, you’re still using Nomad; if you’re deploying one in December of 2023, you’ll probably be interacting with flyd. If we do it right, you mostly won’t have to care.
You can play with this stuff right now.
The Fly Machines API runs on flyd and reserves, starts, and stops individual VMs.
Try Fly for free →
Drawing Most Of The Owl
Over the last couple years, we’ve written about most of the guts of Fly.io:
- How we run containers as VMs in the first place,
- how our WireGuard-backed private networking layer works,
- how we provision Internet Anycasting, and
- how our control plane works (gonna have to rewrite that one soon!).
It took us awhile, but we’re glad to have finally written down our thoughts about one of the last remaining big pieces. With an execution engine, a control plane, and an orchestrator, you’ve got most of our platform! The only huge piece left is fly-proxy, which we have not yet done justice.
We hope this is interesting stuff even if you never plan on running an app here (or building a platform of your own on top of ours). We’re not the first team to come up with a bidding-style orchestrator — they’re documented in that 1988 paper above! But given an entire industry of orchestrators that look like Borg, it’s good to get a reminder of how many degrees of freedom we really have.