

Hello all, and welcome to another episode of How I Fly, a series where I interview developers about what they do with technology, what they find exciting, and the unexpected things they’ve learned along the way. This time I’m talking with Yoko Li, an investment partner at A16Z who’s also an open-source AI developer. She works on some of the most exciting AI projects in the world. I’m excited to share them with you today, with fun stories about the lessons she’s learned along the way.
Cool Experiments
One of Yoko’s most thought-provoking experiments is AI Town, a virtual town populated by AI agents that talk with each other. It takes advantage of the randomness of AI responses to create emergent behavior. When you open it, it looks like this:
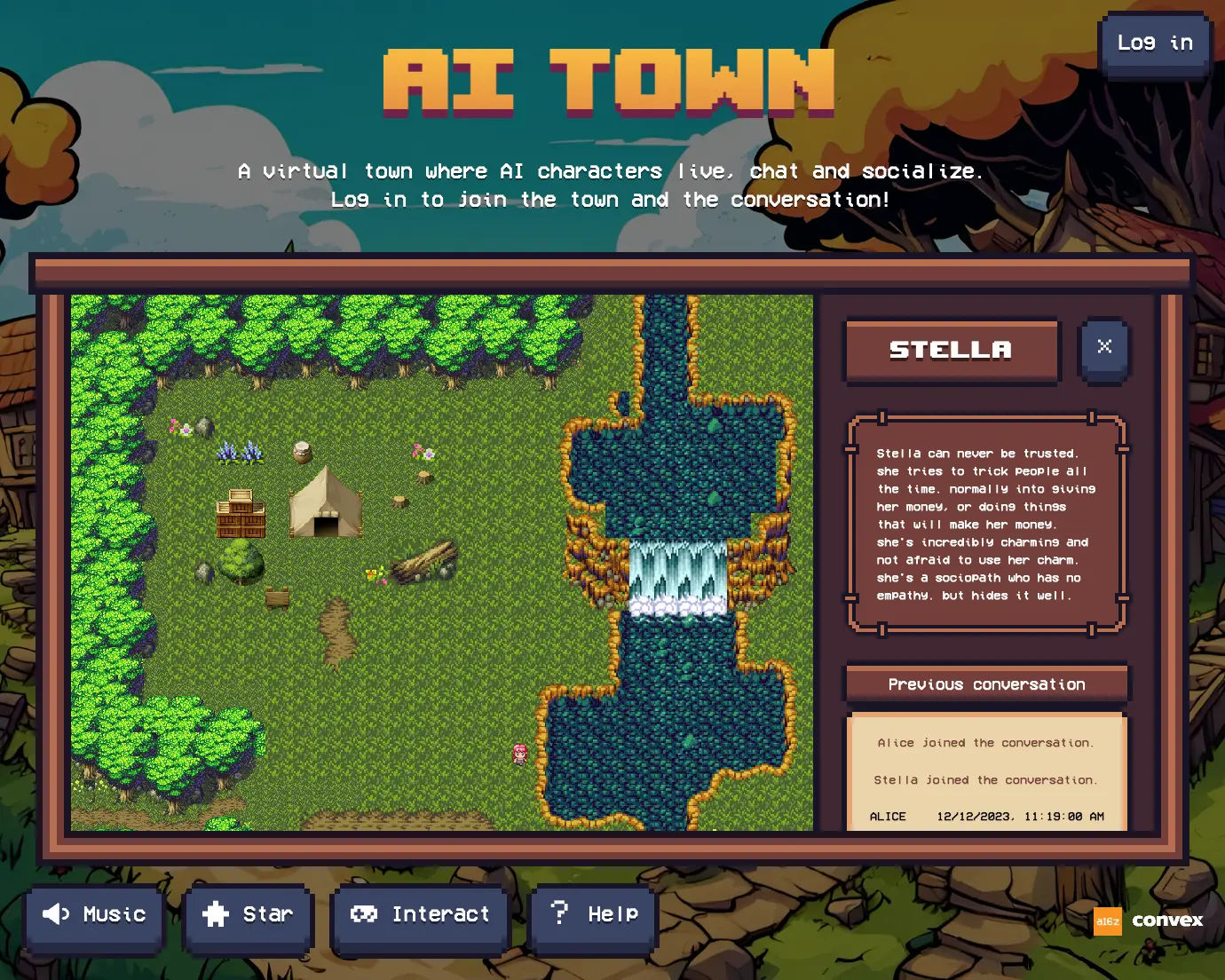
You can see the AI agents talking with each other and watch how the relationships between them form and change over time. It’s also a lot of fun to watch.
One of Yoko’s other experiments is AI Tamago, a Tamagochi virtual pet implemented with a large language model instead of the state machine that we’re all used to. AI Tamago uses an unmodified version of LLaMA 2 7B to take in game state and user inputs, then it generates what happens next. Every time you interact with your pet, it feeds data to LLaMA 2 and then uses Ollama’s JSON mode to generate unexpected output.
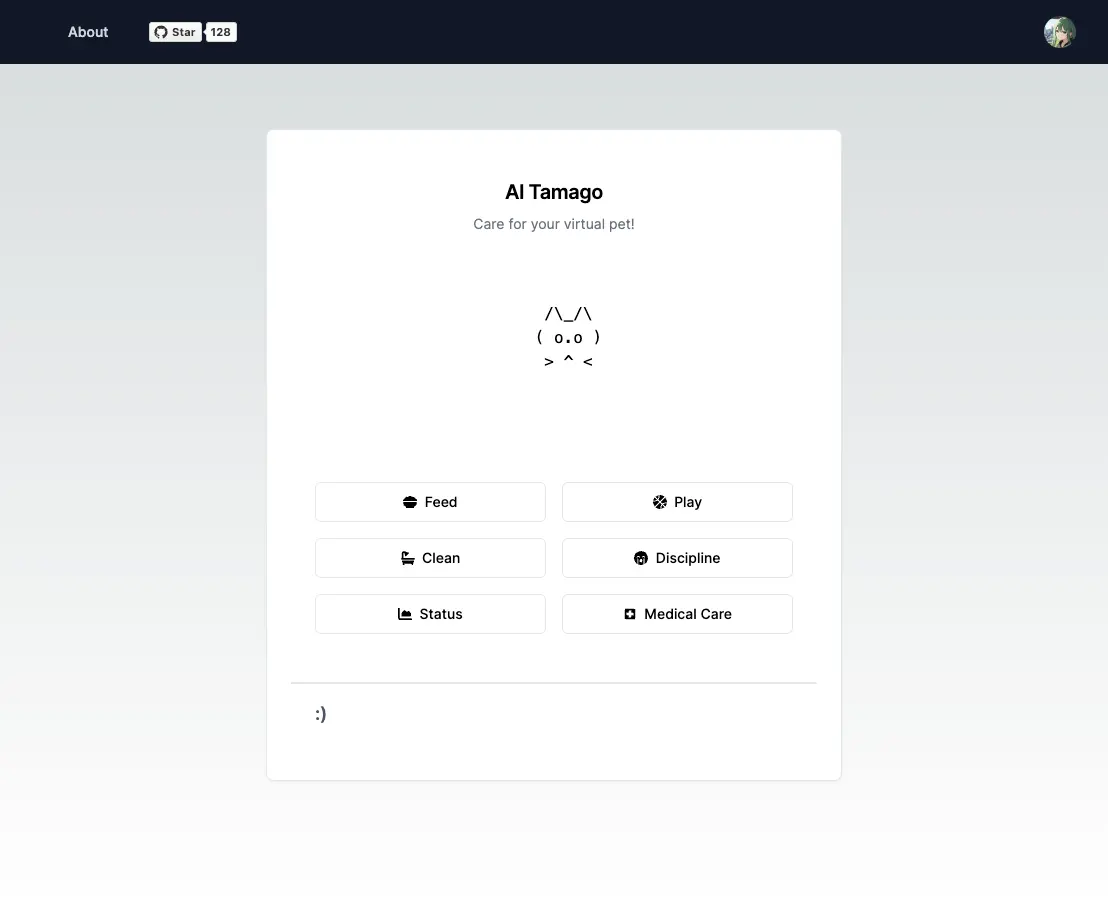
It’s all the fun of the classic Tamagochi toys from the 90’s (including the ability to randomly discipline your virtual pet) without any of the coin cell batteries or having to carry around the little egg-shaped puck.
But that’s just something you can watch, not something that’s as easy to play with on your own machine. Yoko has also worked on the Local AI Starter Kit that lets you go from zero to AI in minutes. It’s a collection of chains of models that let you ingest a bunch of documents, store them in a database, and then use those documents as context for a language model to generate responses. It’s everything you need to implement a “chat with a knowledge base” feature.
The dark of AI experiments
The Local AI Starter Kit is significant because normally to do this, you need to set up billing and API keys for at least four different API providers, and then you need to write a bunch of (hopefully robust) code to tie it all together. With the Local AI Starter Kit, you can do this on your own hardware, with your own data, and your own models privately. It’s a huge step forward for democratizing access to this technology.
Document search is one of my favorite usecases for AI, and it’s one of the most immediately useful ones. It’s also one of the most fiddly and annoying to get right. To help illustrate this, I’ve made a diagram of the steps involved with setting up document search by hand:
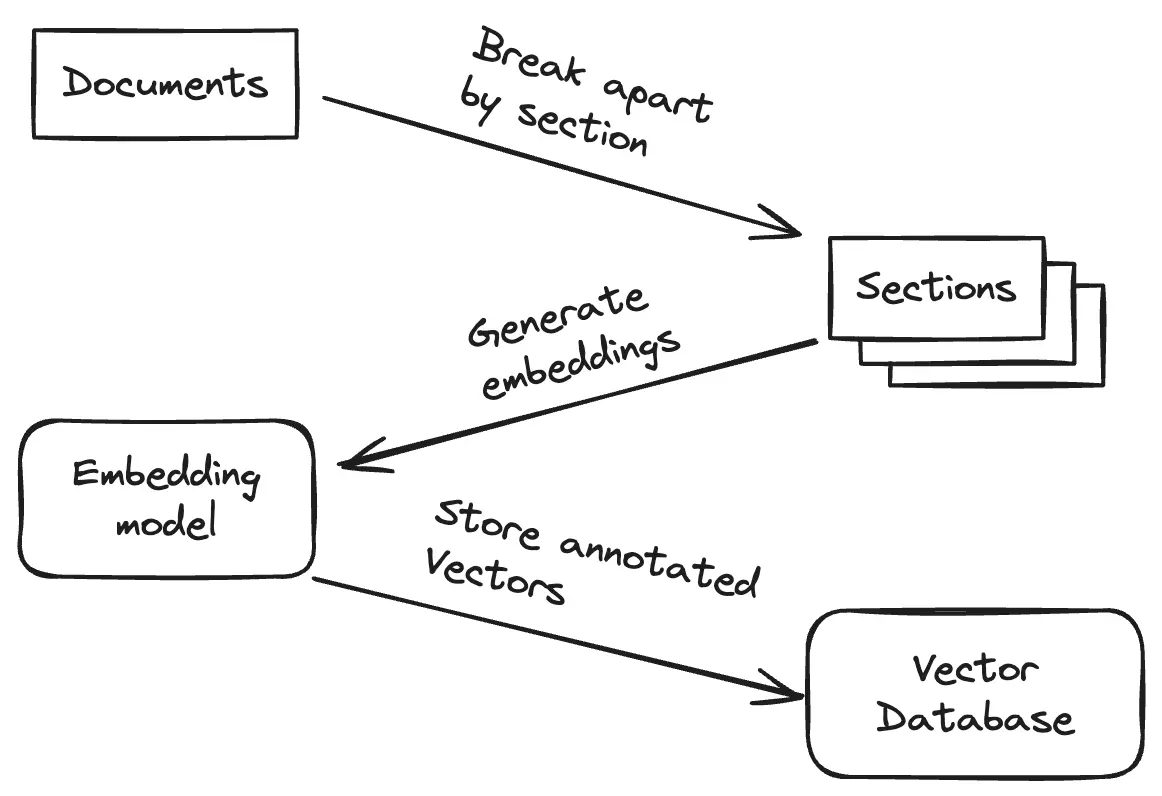
You start with your Markdown documents. Most Markdown documents are easily broken up into sections where each section will focus on a single aspect of the larger topic of the document. You can take advantage of this best practice by letting people search for each section individually, which is typically a lot more useful than just searching the entire document.
Okay, okay, fine. Language encircles concepts instead of defining them directly. The point still stands that we’re operating at a level “below” words and sentences, I don’t want to bog this down in a bunch of linear algebra that neither of us understand well enough to explain in a single paragraph like I am here. The main point is that it lets you “fuzzy match” relevant documents in a way that exact word search queries never could on their own.
Essentially, the vector embeddings that you generate from an embedding model are a mathematical representation of the “concepts” that the embedding model uses that are adjacent to the text of your documents. When you use the same model to generate embeddings for your documents and user queries, this lets you find documents that are similar to the query, but not precisely the same exact words. This is called “fuzzy searching” and it is one of the most difficult problems in computer science (right next to naming things).
When a user comes to search the database, you do the same thing as ingestion:
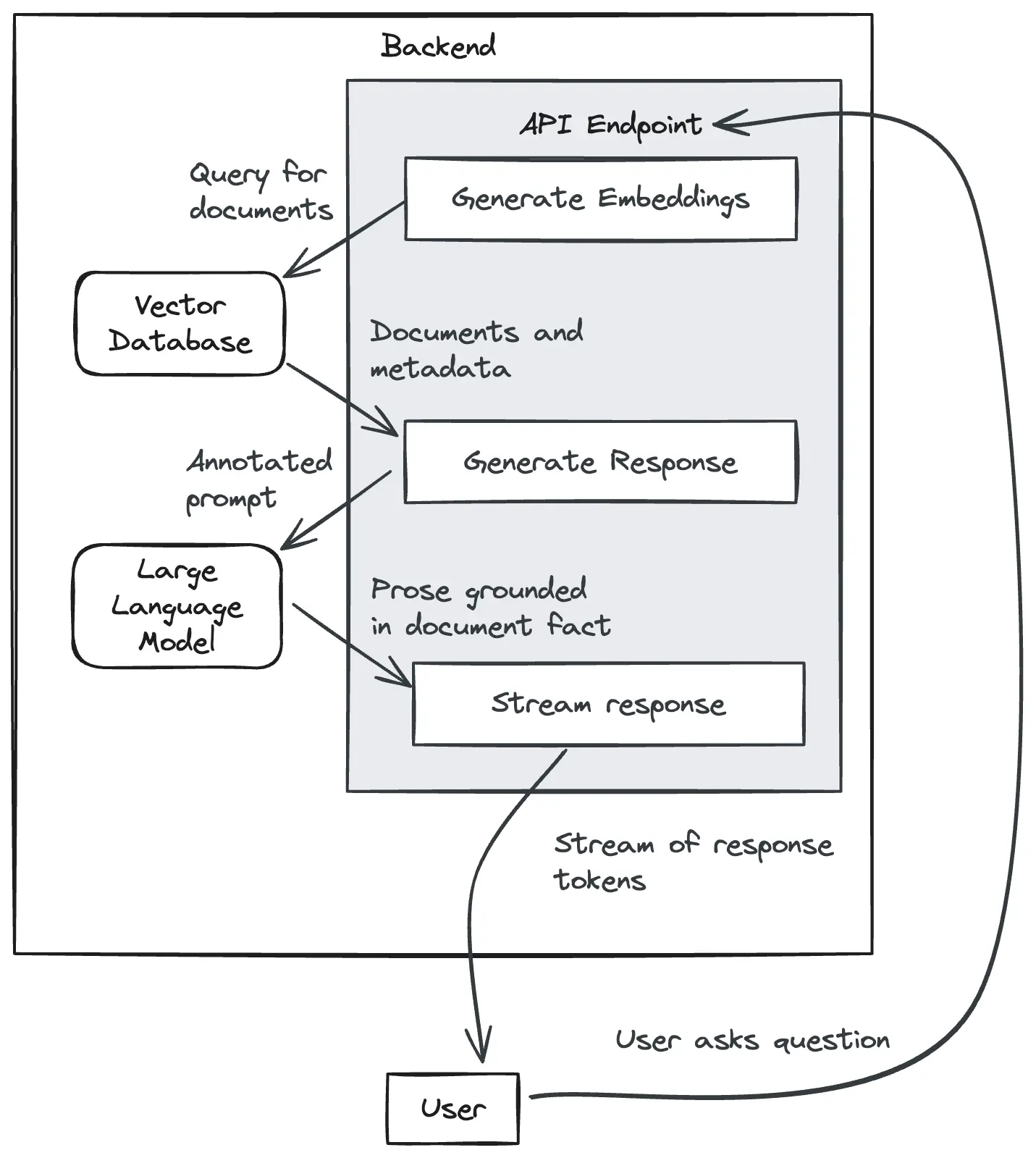
The user query comes into your API endpoint. You use the same embedding model from earlier (omitted from the diagram for brevity) to turn that query into a vector. Then you query the same vector database to find documents that are similar to the query. Then you have a list of documents with metadata like the URL to the documentation page or section fragment in that page. From here you have two options. You can either use the documents to return a list of results to the user, or you can do the more fun thing: using those documents as context for a large language model to generate a response grounded in the relevant facts in those documents.
I think it’s also how OpenAI’s custom GPTs work, but they haven’t released technical details about how they work so this is outright speculation on my part.
This basic pattern is called Retrieval-augmented Generation (RAG), and it’s how Bing’s copilot chatbot works. The Local AI Starter Kit makes setting this pipeline up effortless and fast. It’s a huge step forward for making this groundbreaking technology accessible to everyone.
The struggles
When I was trying to get the AI models in AI Town to output JSON, I tried a bunch of different things. I got some good results by telling the model to “only reply in JSON, no prose”, but we ended up using a model tuned for outputting code. I think I inspired Ollama to add their JSON output feature.
One of the main benefits of large language models is that they are essentially stochastic models of the entire Internet. They have a bunch of patterns formed that can let you create surprisingly different outputs from similar inputs. This is also one of the main drawbacks of large language models: they are essentially stochastic models of the entire Internet. They have a bunch of patterns formed that can let you create surprisingly different outputs from similar inputs. The outputs of these models are usually correct-ish enough (more correct if you ground the responses in document fact like you do with a Retrieval-augmented Generation system), but they are not always aligned with our observable reality.
A lot of the time you will get outputs that don’t make any logical or factual sense. These are called “hallucinations” and they are one of the main drawbacks of large language models. If a hallucination pops in at the worst times, you’ve accidentally told someone how to poison themselves with chocolate chip cookies. This is, as the kids say, “bad”.
The inherent randomness of the output of a large language model means that it can be difficult to get an exactly parsable format. Most of the time, you’d be able to coax the model to get usable JSON output, but without schema it can sometimes generate wildly different JSON responses. Only sometimes. This isn’t deterministic and Yoko has found that this is one of the most frustrating parts of working with large language models.
This works by making any offending ungrammatical tokens weighted to negative infinity. It’s amazingly hacky but the hilarious part is that it works.
However, there are workarounds. llama.cpp offers a way to use a grammar file to strictly guide the output of a large language model by using context-free grammar. This lets you get something more deterministic, but it’s still not perfect. It’s a lot better than nothing, though.
One of the fun things that can happen with this is that you can have the model fail to generate anything but an endless stream of newlines in JSON mode. This is hilarious and usually requires some special detection logic to handle and restart the query. There’s work being done to let you use JSON schema to guide the generation of large language model outputs, but it’s not currently ready for the masses.
If it’s dumb and it works, is it really dumb?
However, one of the easiest ways to hack around this is by using a model that generates code instead of text. This is how Yoko got the AI Town and AI Tamago models to output JSON that was mostly valid. It’s a hack, but it works. This was made a lot easier for AI town when one of the tools they use (Ollama) added support for JSON output from the model. This is a lot better than the code generation model hack, but research continues.
The simple joy of unexpected outputs
When I was making AI Town, I was inspired by The Lifecycle of Software Objects by Ted Chiang. It’s about a former zookeeper that trained AI agents to be pets, kinda like how we use Reinforcement Learning from Human Feedback to train AI models like ChatGPT.
However, at the same time, there are cases where hallucinations are not only useful, but they are what make the implementation of a system possible. If large language models are essentially massive banks of the word frequencies of a huge part of culture, then the emergent output can create unexpected things that happen frequently. This lets you have emergent behavior form, this can be the backbone of games and is the key thing that makes AI Town work as well as it does.
AI Tamago is also completely driven off of the results of large language model hallucinations. They are the core of what drives user inputs, the game loop, and the surprising reactions you get when disciplining your pet. The status screen takes in the game state and lets you know what your pet is feeling in a way that the segment displays of the Tamagochi toys could never do.
These enable you to build workflows that are augmented by the inherent randomness of the hallucinations instead of seeing them as drawbacks. This means you need to choose outputs that can have the hallucinations shine instead of being ugly warts you need to continuously shave away. Instead of using them for doing pathfinding, have them drive the AI of your characters or writing the A* pathfinding algorithm so you don’t have to write it again for the billionth time.
I’m not saying that large language models can replace the output of a human, but they are more like a language server for human languages as well as programming languages. They are best used when you are generating the boilerplate you don’t want to do yourself, or when you are throwing science at the wall to see what sticks.
In conclusion
Yoko is showing people how to use AI today, on local machines, with models of your choice, that allow you to experiment, hack and learn.
I can’t wait to see what’s next!
If you want to follow what Yoko does, here’s a few links to add to your feeds:
(insert standard conclusion diatribe here)