

Fly.io turns Docker images into running VMs on physical servers all over the world. We built an API for booting VMs very quickly. Here’s what you need to know.
Fly Machines are VMs with a fast REST API that can boot instances in about 300ms.
Our proxy can boot Fly Machines for you, and you can shut them down when they’re idle. Which means you can cost-effectively create VMs and keep them standing by to handle new requests.
If you’re already running an app on Fly.io, here’s what you need to know. Machines are basically the same as the VMs we manage with our orchestration system (Nomad). When you deploy an app, we create new VMs and destroy the old ones with your preferred image. Fly Machines are one level lower, and let developers manage individual VMs.
We built Machines for us. Our customers want their apps to scale to zero, mostly to save money. Also because it feels right. An app that isn’t doing anything shouldn’t be running. Fly Machines will help us ship apps that scale to zero sometime this year.
Fly Machines may be useful to you, too. A lot of y'all want to build your own functions-as-a-service. You can build a FaaS with Fly Machines.
How to boot VMs in a hurry
We said we want our VMs to boot fast. They already do; Firecracker is pretty darn fast to boot a given executable on a given host. Our job is to get our own plumbing out of your way, and get you close to local-Firecracker speeds.
Spinning up a VM as fast as possible on a server somewhere is an exercise in reducing infrastructure latency. We need to play latency whack-a-mole.
When you ask for a VM, you wait for network packets to travel to an API somewhere. Then you wait for them to come back. The API is also, at minimum, talking to the host your job will run on. If all your users are in Virginia and your API is in Virginia and the hardware running Firecrackers is in Virginia, this might take 20-50ms.
If your users are in Sydney and the hardware for the Firecrackers are in Sydney and the API is in Virginia, “boot me a VM” takes more like 300ms. Three tenths of a second just waiting for light to move around is not fast.
We’re not done. You need something to run, right? Firecracker needs a root filesystem. For this, we download Docker images from our repository, which is backed by S3. This can be done in a few seconds if you’re near S3 and the image is smol. It might take several minutes (minutes!) if you’re far away and the image is chonk.
We solve this by making you create machines ahead of time. Accountants (not the TikTok kind; actual accountants) call this “amortization” – pay the cost up front, yield the benefit over time.
The slow part
Here’s what happens when you call the create machine endpoint:
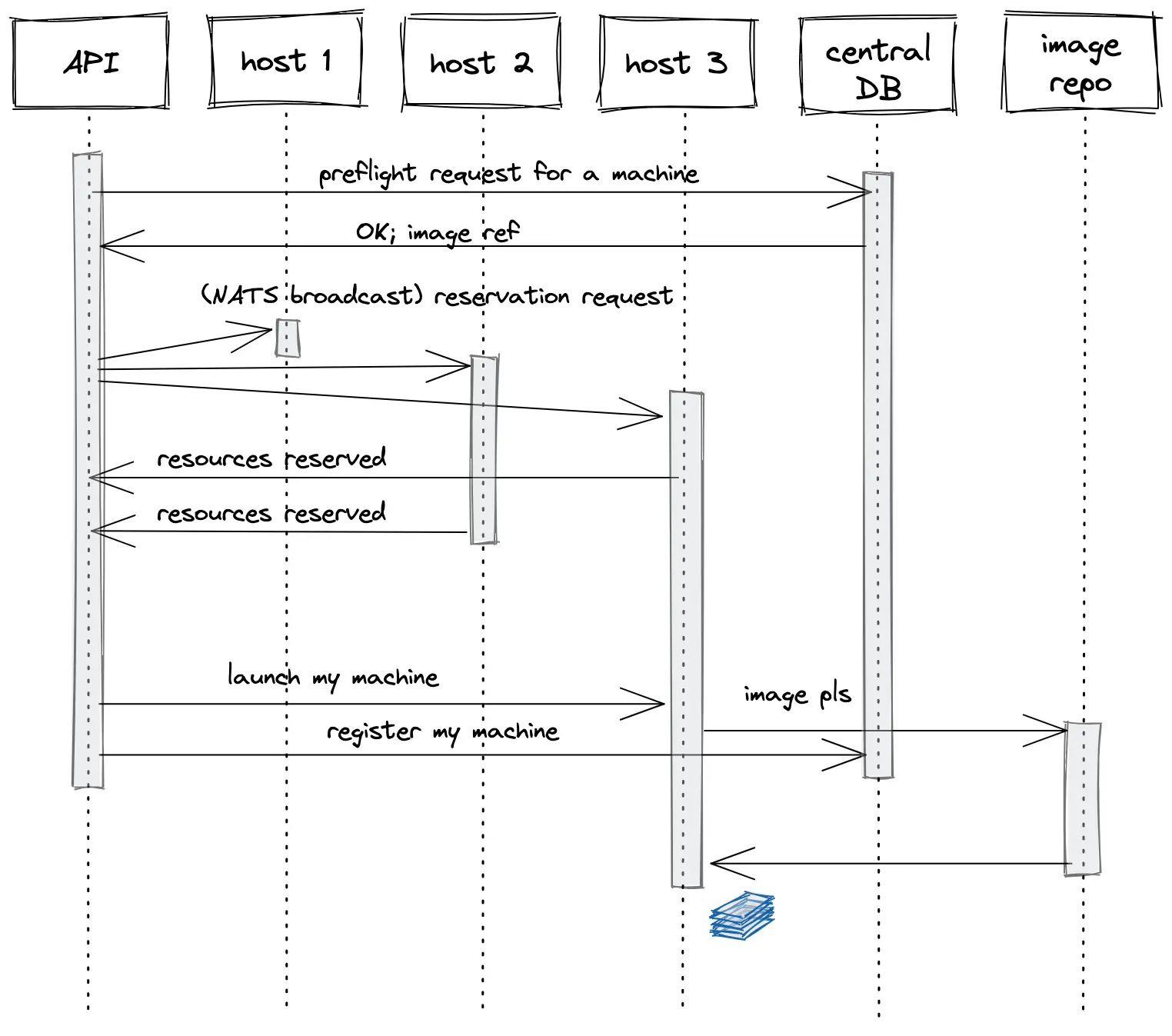
If you’re an app developer in Los Angeles and you want a machine in São Paulo, your request gets routed to your friendly local API server. We run API servers in every region, so this part of the process is fast.
The API server makes a preflight request to our centralized database in Virginia, which gives back a yay (or nay!) and an immutable Docker image URL.
Our database in Virginia has to be looped in on machine creation. We want a strongly-consistent record that machines exist. We also want to make sure you can’t create a machine if you’re 8 months behind on bills or got banned for mining cryptocurrency with a stolen credit card.
The Los Angeles API instance then broadcasts a NATS message to the available hosts in São Paulo saying “hey, reserve me a machine with these specs”. Hosts with resources to spare reserve a slice of their capacity and reply with information about what they have to offer.
The API server evaluates each host’s offer, picks one, and says “OK, host, create a machine for reservation X”. The API server then records a machine record in our centralized database. The other hosts garbage-collect the unused reservations a few seconds later.
You might be thinking “if I’m in Los Angeles and I request a machine in São Paulo, won’t it take like a second for that whole dance to happen?” It would, yes.
You might also be thinking “pulling that image from a remote repository was probably soul-crushingly slow, right?” Also true! You don’t want to do that any more times than you need to.
We made machines really cheap to create and keep stopped. In fact, right now, you pay for image storage; that’s it. What we want you do is: create machines ahead of time and start them when you need them.
The fast part
You should create machines just before you need them. Slightly earlier than just-in-time. All the stuff I just told you about is necessary to get to this point, but the protein is here: we designed Fly Machines for fast starts.
When you’re ready, you start a machine in São Paulo with a request to the nearest API server. This time, though, there’s no need to wait on our database in Virginia. The central accounting is done and the API server knows exactly which host it needs to talk to. And the OCI image for the VM’s filesystem is ready to go.
Here’s what the start machine endpoint does:

Now the start is fast. How fast?
When you run fly machine start e21781960b2896, the API server knows that e21781960b2896 is owned by a host in São Paulo. It then sends a message directly to that host saying “start it up”. This message travels as fast as physics allows.
The host receives the start message…and starts the machine. It already has the image stored locally, so it doesn’t need to wait on an image pull.
If you’re in Los Angeles and start your machine in São Paulo, the “start” message gets where it needs to go in ~150ms. But if you’re in Los Angeles and start a machine in Los Angeles, the “start” message might arrive in ~10ms.
The lesson here is “start machines close to your users”; the operation is very fast. Here’s something cool about this, though: You don’t necessarily start the machine from where you are; an app can do it for you. In fact, this is kind of the point. Your application logic should be close to your users’ machines.
Or, you can forego the app and let fly-proxy boot machines when HTTP requests arrive. It can do all this for you.
I should clarify: our infrastructure is fast to run start operations. Your application boot time is something you should optimize. We can’t help with that (yet!)
Stopping and scaling to zero
Stop commands are fast too. You may not want to issue stop commands, though. If your machine should stop when it’s idle, there’s a better way.
Fly.io users have been requesting “scale to zero” since January 1st, 1970 at 00:00:00 UTC. Scaling up is pretty easy; it’s usually safe to boot a new VM and add it to a load balancer. Scaling down is harder—stop a VM at the wrong time and shit breaks.
So here’s how we modeled this: when you use Fly.io machines to run apps that need to scale down, make your process exit when it’s idle. That’s it. You’ve exited the container, effectively stopping the machine, but it’s intact to pick up a future start request from a clean slate.
This works because your in-machine process has a strongly-consistent view of local activity and can confidently detect “idle”.
Play with the Machines API
If you’ve got a Fly.io account, you can play with the Fly Machines API right now—even if you’re not ready to [build your own FaaS](https://fly.io/docs/app-guides/functions-with-machines).
Try Machines →
How Fly Machines will frustrate you (the emotional cost of simplicity)
One thing you may have noticed about our design: machines are pinned to specific hardware in our datacenters. This is a tradeoff that buys simplicity at the risk of your patience.
Pinning machines to specific hardware means that if the PSU on that host goes pop, your machine won’t work (kind of; we run redundant PSUs). Capacity issues will create more surprising failures. If you create a biggish 64GB RAM machine and leave it stopped, we might be out of capacity on that specific host when you attempt to start it back up.
We will mostly shield you from capacity issues, but you should definitely be prepared for the eventuality that your first-choice hardware is indisposed. Which really just means: plan to have two machines for redundancy.
The good news is that our API is pretty fast. Creating a machine is relatively slow, but you can do it in a pinch. If a machine fails to start, you can usually get another one running in a few seconds.
The best way to use machines is to think of a list of operations in priority order. If you’re trying to run some user code, come up with a list like this:
- Start machine X in Chicago. If that fails,
- Start machine Z in New Jersey. If that fails,
- Launch new machine in Chicago. If that fails,
- Launch new machine in New Jersey. If that fails,
- Launch new machine somewhere in the US. If that fails,
- Check your internet connection (or our status page). That should not fail.
This cycle will account for all the predictable failures and should get you a machine any time you want one.
Pricing (the monetary cost of simplicity)
Running machines costs the same as running normal VM instances. The same goes for bandwidth, RAM, and persistent disks.
Stopped machines, though, are something we could use your feedback on. There’s a cost to keeping these things around. Right now, we just charge you for storage when a machine isn’t running. Like $0.15/mo for a 1GB Docker image.
Questions? Comments? Pricing ideas? Vitriol? Comment in our forum thread.