
With Fly.io, you can get your app running globally in a matter of minutes, and with LiteFS, you can run SQLite alongside your app! Now we’re introducing LiteFS Cloud: managed backups and point-in-time restores for LiteFS. Try it out for yourself!
When we started the LiteFS project a year ago, we started more with an ideal in mind rather than a specific implementation. We wanted to make it possible to not only run distributed SQLite but we also wanted to make it… gasp… easy!
There were hurdles that we expected to be hard, such as intercepting SQLite transaction boundaries via syscalls or shipping logs around the world while ensuring data integrity. But there was one hurdle that was unexpectedly hard: maintaining a consistent view from the application’s perspective.
LiteFS requires write transactions to only be performed at the primary node and then those transactions are shipped back to replicas instantaneously. Well, almost instantaneously. And therein lies the crux of our problem.
Let’s say your user sends a write request to write to the primary node in Madrid and the user’s next read request goes to a local read-only replica in Rio de Janeiro. Most of the time LiteFS completes replication quickly and everything is fine. But if your request arrives a few milliseconds before data is replicated, then your user sees the database state from before the write occurred. That’s no good.
How exactly do we handle that when our database lives outside the user’s application?
Our initial series of failures, or how we tried to teach distributed systems to users
Our first plan was to let LiteFS users manage consistency themselves. Every application may have different needs and, honestly, we didn’t have a better plan at the time. However, once we started explaining how to track replication state, it became obvious that it was going to be an untenable approach. Let’s start with a primer and you’ll understand why.
Every node in LiteFS maintains a replication position for each database which consists of two values:
- Transaction ID (TXID): An identifier that monotonically increases with every successful write transaction.
- Post-Apply Checksum: A checksum of the entire database after the transaction has been written to disk.
You can read the current position from your LiteFS mount from the -pos file:
$ cat /litefs/my.db-pos
000000000042478b/8b73bc1d07d84988
This example shows that we are at TXID 0x42478b (or 4,343,691 in decimal) and the checksum of our whole database after the transaction is 8b73bc1d07d84988. A replica can detect how far it’s lagging behind by comparing its position to the primary’s position. Typically, a monotonic transaction ID doesn’t work in asynchronous replication systems like LiteFS but when we couple it with a checksum it allows us to check for divergence so the pair works surprisingly well.
LiteFS handles the replication position internally, however, it would be up to the application to check it to ensure that its clients saw a consistent view. This meant that the application would have needed to have its clients track the TXID from their last write to the primary and then the application would have to wait until its local replication caught up to that position before it could serve the request.
That would have been a lot to manage. While you may find the nuts and bolts of replication interesting, sometimes you just want to get your app up and running!
Let’s use a library! Er, libraries.
Teaching distributed systems to each and every LiteFS user was not going to work. So instead, we thought we could tuck that complexity away by providing a LiteFS client library. Just import a package and you’re done!
Libraries are a great way to abstract away the tough parts of a system. For example, nobody wants to roll their own cryptography implementation so they use a library. But LiteFS is a database so it needs to work across all languages which means we needed to implement a library for each language.
Actually, it’s worse than that. We need to act as a traffic cop to redirect incoming client requests to make sure they arrive at the primary node for writes or that they see a consistent view on a replica for reads. We aren’t able to redirect writes at the data layer so it’s typically handled at the HTTP layer. Within each language ecosystem there can be a variety of web server implementations: Ruby has Rails & Sinatra, Go has net/http, gin, fasthttp, and whatever 12 new routers came out this week.
Moving up the abstraction stack
Abstraction often feels like a footgun. Generalizing functionality across multiple situations means that you lose flexibility in specific situations. Sometimes that means you shouldn’t abstract but sometimes you just haven’t found the right abstraction layer yet.
For better or for worse, HTTP & REST-like applications have become the norm in our industry and some of the conventions provide a great layer for LiteFS to build upon. Specifically, the convention of using GET requests for reading data and the other methods (POST, PUT, DELETE, etc) for writing data.
Instead of developers injecting a LiteFS library into their application, we built a thin HTTP proxy that lives in front of the application.
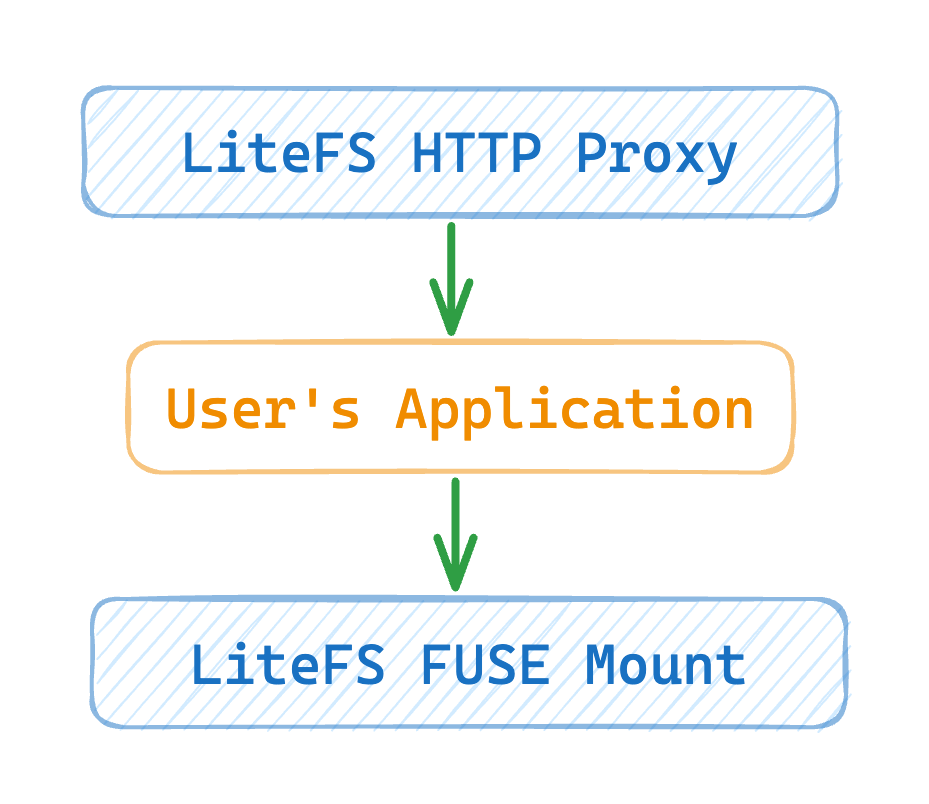
This approach has let us manage both the incoming client side via HTTP as well as the backend data plane via our FUSE mount. It lets us isolate the application developer from the low-level details of LiteFS replication while making it feel like they’re developing against vanilla SQLite.
How it works
The LiteFS proxy design is simple but effective. As an example, let’s start with a write request. A user creates a new order so they send a POST /orders request to your web app. The LiteFS proxy intercepts the request & parses the HTTP headers to see that it’s a POST write request. If the local node is a replica, the proxy forwards the request to the primary node.
If the local node is the primary, it’ll pass the request through to the application’s web server and the request will be processed normally. When the response begins streaming out to the client, the proxy will attach a cookie with the TXID of the newly-written commit.
When the client then sends a GET read request, the LiteFS proxy again intercepts it and parses the headers. It can see the TXID that was set in the cookie on the previous write and the proxy will check it against the replication position of the local replica. If replication has caught up to the client’s last write transaction, it’ll pass through the request to the application. Otherwise, it’ll wait for the local node to catch up or it will eventually time out. The proxy is built into the litefs binary so communication with the internal replication state is wicked fast.
Preventing laggards
The proxy provides another benefit: health checks. Networks and servers don’t always play nice when they’re communicating across the world and sometimes they get disconnected. The proxy hooks into the LiteFS built-in heartbeat system to detect lag and it can report the node as unhealthy via a health check URL when this lag exceeds a threshold.
If you’re running on Fly.io, we’ll take that node out of rotation when health checks begin reporting issues so users will automatically get routed to a different, healthy replica. When the replica reconnects to the primary, the health check will report as healthy and the node will rejoin.
The Tradeoffs… there’s always tradeoffs!
Despite how well the LiteFS proxy works in most situations, there’s gonna be times when it doesn’t quite fit. For example, if your application cannot rely on cookies to track application state then the proxy won’t work for you.
There are also frameworks, like Phoenix, which can rely heavily on websockets for live updates so this circumvents your traditional HTTP request/response approach that LiteFS proxy depends on. Finally, the proxy provides read-your-writes guarantees which may not work for every application out there.
In these cases, let us know how we can improve the proxy to make it work for more use cases! We’d love to hear your thoughts.
Diving in further
The LiteFS proxy makes it easy to run SQLite applications in multiple regions around the world. You can even run many legacy applications with little to no change in the code.
If you’re interested in setting up LiteFS, check out our Getting Started guide. You can find additional details about configuring the proxy on our Built-in HTTP Proxy docs page.