

Fly.io runs apps close to users around the world, by taking containers and upgrading them to full-fledged virtual machines running on our own hardware around the world. Sometimes those containers run SQLite and we make that easy too. Give us a whirl and get up and running quickly.
If you scour Hacker News & Reddit for advice about databases, some common words of caution are that SQLite doesn’t scale or that it is a single-user database and it’s not appropriate for your web-scale application.
Like any folklore, it has some historical truth. But it’s also so wildly out-of-date.
In our last post, we talked about the rollback journal. That was SQLite’s original transactional safety mechanism and it left much to be desired in terms of scaling.
In 2010, SQLite introduced a second method called the write-ahead log, or as it’s more commonly referred to: the WAL.
Refresher on the rollback journal
The rollback journal worked by copying the old version of changed pages to another file so that they can be copied back to the main database file if the transaction rolls back.
The WAL does the opposite. It writes the new version of a page to another file and leaves the original page in-place in the main database file.
So how does this simple change enable SQLite to scale? Let’s revisit our sandwich shop example from the last post to see how the WAL would make things run more smoothly.
Sandwiches at scale
In our sandwich shop example, we had to choose between a single sandwich maker making sandwiches and one or more inventory specialists inventorying ingredients. We couldn’t do both at the same time. This is how the rollback journal works; a writer can alter the database or readers can read from the database—but not both at the same time.
This is a problem since making a complicated, time-consuming sandwich will prevent inventory from being taken. Also, a single slow inventory counter will prevent any sandwiches from being made.
A simple solution would be to take a photo of every ingredient after a sandwich is made. That way inventory counters could look at the photos to take inventory. However, it would be slow and inefficient to take a photo of every ingredient after a sandwich since many ingredients wouldn’t change. For example, if you’re making a grilled cheese then you’re not going to touch the pickles, right? Right!?
A better solution would be to only take photos of the ingredients you took from after each sandwich. You can add these photos to a binder and now the inventory folks can see a point-in-time snapshot of the ingredients without interfering with the sandwich maker.
This is how the WAL works, in concept.
Enabling the sandwich log
Let’s create a sandwiches.db that will store our current count of ingredients:
CREATE TABLE ingredients (
id INTEGER PRIMARY KEY,
name TEXT,
count INTEGER
);
To enable our write-ahead log journaling mode, we just need to use the journal_mode PRAGMA:
PRAGMA journal_mode = wal;
Internally, this command performs a rollback journal transaction to update the database header so it’s safe to use like any other transaction. The database header has a read & write version at bytes 18 & 19, respectively, that are used to determine the journal mode. They’re set to 0x01 for rollback journal and 0x02 for write-ahead log. They’re typically both set to the same value.
Altering the ingredient count
Now that we are using the WAL, we can add our initial inventory counts:
INSERT INTO ingredients (name, count)
VALUES ('onions', 10), ('tomatoes', 5), ('lettuce', 20);
Instead of updating our sandwiches.db database file, our change is written to a sandwiches.db-wal file in the same directory. Let’s fire up our hexdump tool and see what’s going on.
Starting with the WAL header
The WAL file starts with a 32-byte header:
377f0682 002de218 00001000 00000000 5a20ee38 f926b5d3 0dd5236d 9972220b
Most SQLite files start with a magic number and the WAL is no exception. Every WAL file starts with either 0x377f0682 or 0x377f0683 which indicate whether checksums in the file are in little-endian or big-endian format, respectively. Nearly all modern processors are little-endian so you’ll almost always see 0x377f0682 as the first 4 bytes of a SQLite WAL file.
Next, the 0x002de218 is the WAL format version. This is the big-endian integer representation of 3007000 which means it’s the WAL version created in SQLite 3.7.0. There’s currently only one version number for WAL files.
The next four bytes, 0x00001000, are the page size. We’re using the default page size of 4,096 bytes. The next four after that are 0x00000000 which is the checkpoint sequence number. This is a number that gets incremented on each checkpoint. We’ll discuss checkpointing later in this post.
After that, we have an 8-byte “salt” value of 0x5a20ee38f926b5d3. The term “salt” is typically used in cryptography (and sandwiches, actually) but in this case it’s a little different. Sometimes the WAL needs to restart from the beginning but it doesn’t always delete the existing WAL data. Instead it just overwrites the previous WAL data.
In order for SQLite to know which WAL pages are new and which are old, it writes the salt to the WAL header and every subsequent WAL frame. If SQLite encounters a frame whose salt doesn’t match the header’s salt, then it knows that it’s a frame from an old version of the WAL and it ignores it.
Finally, we have an 8-byte checksum of 0x0dd5236d9972220b which is meant to verify the integrity of the WAL header and prevent partial writes. If we accidentally overwrite half the header and then the computer shuts down, we can detect that by calculating and comparing the checksum.
Adding WAL entries
The WAL works by appending new data to the -wal file so we’ll see an entry for a single page in our WAL file. It starts with a 24-byte header and then writes 4,096 bytes of page data.
00000002 00000002 5a20ee38 f926b5d3 5333783e 42122b82 [page data...]
The first 4 bytes, 0x00000002, are the page number for the entry. This is saying that our page data following the header is meant to overwrite page 2.
The next 4 bytes, also 0x00000002, indicate the database size, in pages, after the transaction. This field actually performs double duty. For transactions that alter multiple pages, this field is only set on the last page in the transaction. Earlier pages set it to zero. This means we can delineate sections of the WAL by transaction. It also means that a transaction isn’t considered “committed” until the last page is written to the WAL file.
After that we see our salt value 0x5a20ee38f926b5d3 copied from the header. This lets us know that it is a contiguous block of WAL entries starting from the beginning of the WAL. Finally, we have an 8-byte checksum of 0x5333783e42122b82 which is computed based on the WAL header checksum plus the data in the WAL entry and page data.
Overlaying our WAL pages
Every transaction that occurs will simply write the new version of changed pages to the end of the WAL file. This append-only approach gives us an interesting property. The state of the database can be reconstructed at any point in time simply by using the latest version of each page seen in the WAL starting from a given transaction.
In the diagram below, we have the logical view of a b-tree inside SQLite and an associated WAL file with 3 transactions. Before the WAL file exists, we have three pages in our database, represented in black.
The first transaction (in green) updates pages 1 and 2. A snapshot of the database after this transaction can be constructed by using WAL entries for pages 1 and 2 and the original page from the database for page 3.
Our second transaction (in red) only updates page 2. If we want a snapshot after this transaction, we’ll use page 1 from the first transaction, page 2 from the second transaction, and page 3 from the database file.
The last transaction (in orange) updates pages 2 & 3 so the entire b-tree is now read from the WAL.
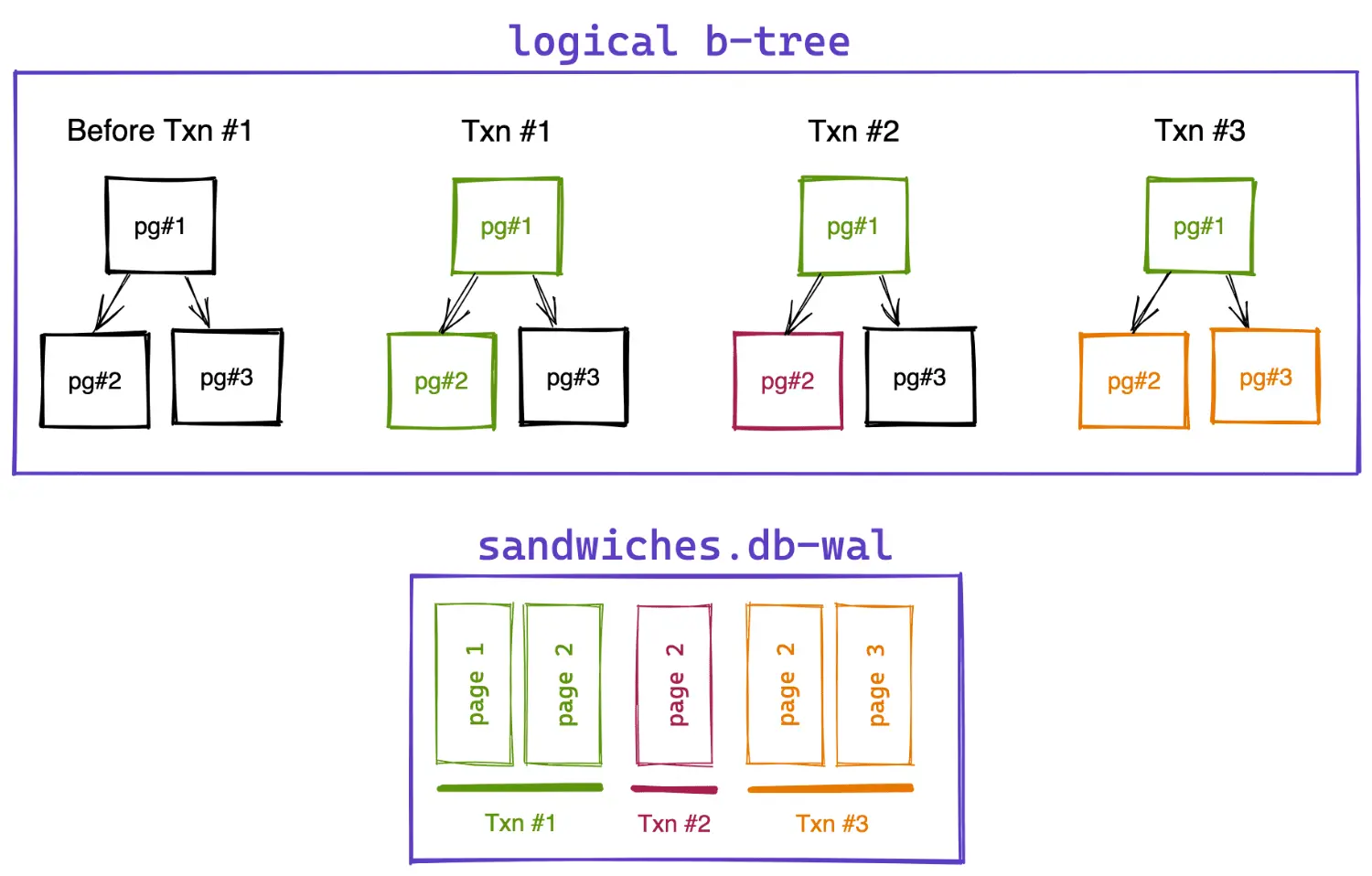
The beauty of this approach is that we are no longer overwriting our pages so every transaction can reconstruct its original state from when it started. It also means that write transactions can occur without interfering with in-progress read transactions.
Retiring our gastronomical photo album
You may have noticed one problem with our append-only album of ingredient photos—it keeps getting bigger. Eventually it will become too large to handle. Also, we really don’t care about the ingredient photos that we took 400 sandwiches ago. We only want to allow sandwich makers and inventory counters to do their work at the same time.
In SQLite, we resolve this issue with the “checkpointing” procedure. Checkpointing is when SQLite copies the latest version of each page in the WAL back into the main database file. In our diagram below, page 1 is copied from the first transaction but pages 2 & 3 are copied from the third transaction. The prior versions of page 2 are ignored because they are not the latest.
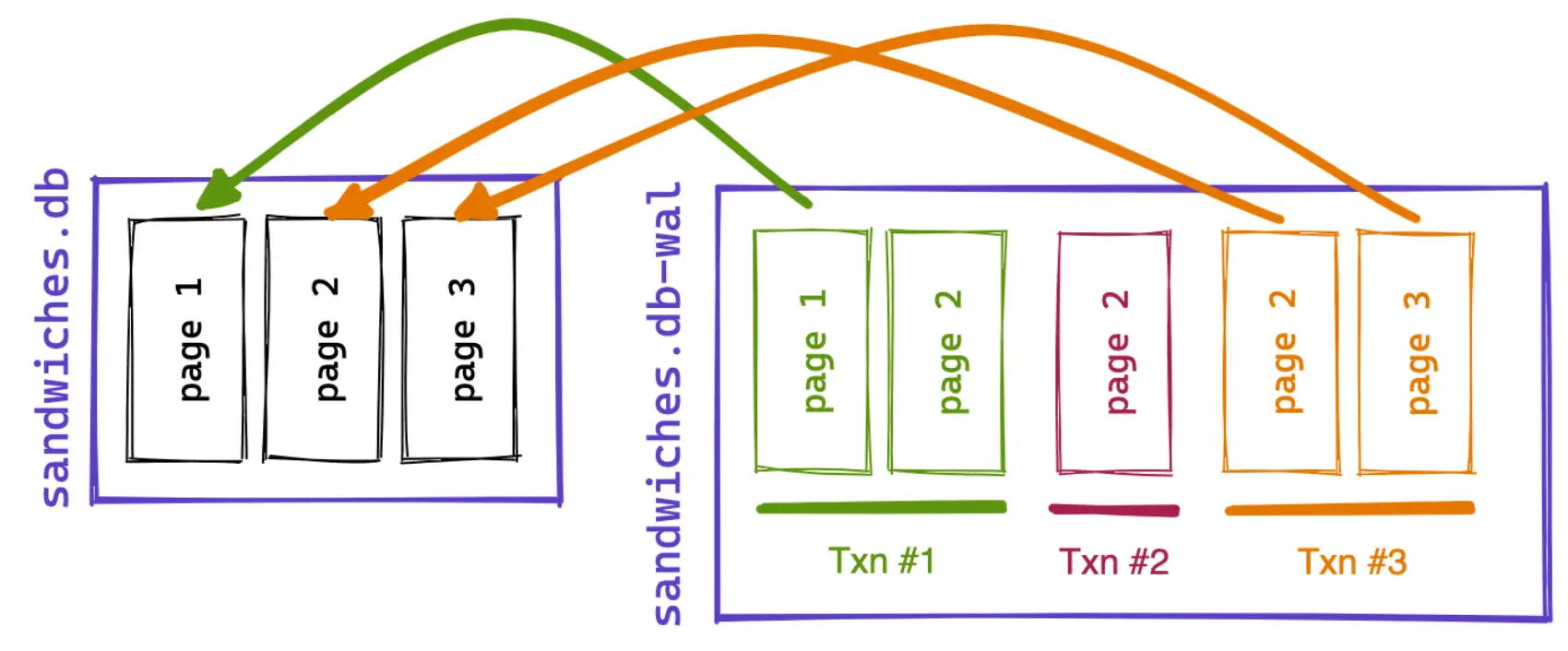
SQLite can perform this process incrementally when old transactions are not in use but eventually, it needs to wait until there are no active transactions if it wants to fully checkpoint and restart the WAL file.
This naive approach can be problematic on databases that constantly have open transactions as SQLite will not force a checkpoint on its own and the WAL file can continue to grow. You can force SQLite to block new read & write transactions so it can restart the WAL by issuing a wal_checkpoint PRAGMA:
-- restart but don't truncate WAL
PRAGMA wal_checkpoint(RESTART);
or
-- restart and truncate WAL to zero bytes
PRAGMA wal_checkpoint(TRUNCATE);
Building a photo index
As our photo album grows, it gets slower to find the latest version of each photo in order to reconstruct our sandwich shop state. You have to start from the beginning of the album and find the last version of a page every time you want to look up a photo.
A better option would be to have an index in the photo album that lists all the locations of photos for each ingredient. Let’s say you have 20 photos of banana peppers. You can look up “banana peppers” in the index and find the location of the latest one in the album.
Writing our index
SQLite builds a similar index and it’s stored in the “shared memory” file, or SHM file, next to the database and WAL files.
But SQLite’s index is a bit funny looking at first glance: it’s a list of page numbers and a hash map. The goal of the index is to tell the SQLite client the latest version of a page in the WAL up to a given position in the WAL. Since each transaction starts from a different position in the WAL, they can have different answers to exactly which version of a page they see.
The SHM index is built out of 32KB blocks that each hold 4,096 page numbers and a hash map of 8,192 slots. When WAL entries are written, their page numbers are inserted into the SHM’s page number list in WAL order. Then a hash map position is calculated based on the page number and the index of the page number is stored in the hash map.
Clear as mud? Let’s walk through an example.
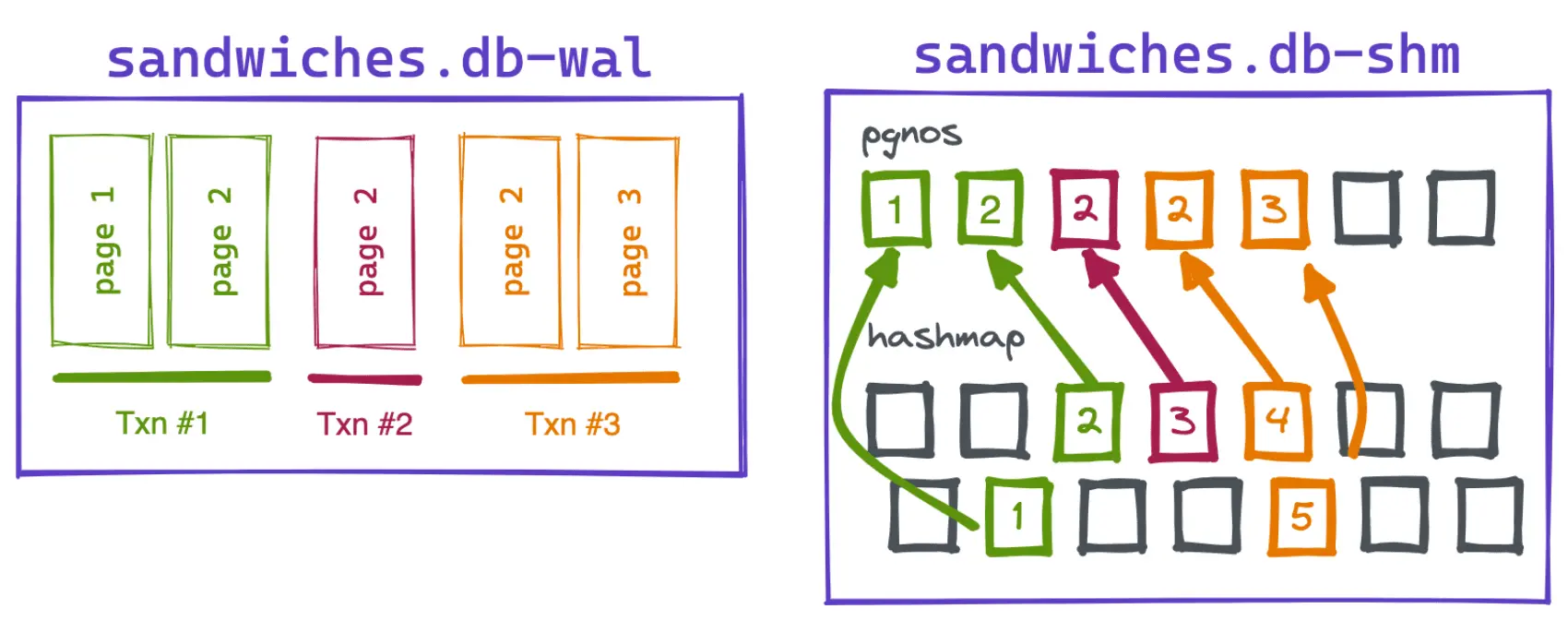
In the diagram above, our first transaction in the WAL (green) updates pages 1 & 2. They get written to the WAL, but the page numbers are also added to the page numbers list in the SHM file. SQLite calculates a hash map slot position for each page using the formula: (pgno * 383)%8192. In the hash map slot, we’ll write the index of the page in our page number list. This is also 1 & 2, respectively. Don’t read too much into the exact hash map positions in the diagram. There’s some loss of fidelity in simplifying 8,192 slots down to 14!
This hash-based mapping will generally spread out our page numbers across our hash map and leave empty space between them. Also, we are guaranteed to have a lot of empty slots in the hash map since there are double the number of hash map slots as there are page number spots. This will be useful when looking up our pages later.
Our next transaction (red) only updates page 2. We’ll write that page to the third entry in our page number list. However, when we calculate our hash map position, we have a collision with the entry for page 2 in transaction 1. They both point at the same slot. So instead of writing to that slot, we’ll write our page number list index, 3, to the next empty slot.
Finally, our third transaction updates pages 2 & 3. We’ll write those to indexes 4 & 5 in our page number list and then write those indexes to our hash map slots. Again, our page 2 collides with updates in the first two transactions so we’ll write the index to the first empty slot after the hash map position.
Reading our index
Now that we have our index built, we can quickly look up the latest version of any given page for a transaction. Let’s say we’ve started a read transaction just after transaction #2 completed. We only want to consider versions of pages in the WAL up to entry #3 since WAL entries in index 4 & 5 occurred after our read transaction started.
If we want to look up page 2, we’ll first calculate the hash position and then read all the indexes until we reach an empty slot. For page 2, this is indexes 2, 3, & 4. Since our transaction started at entry #3, we can ignore entries after index 3 so we can discard index 4. Out of this set, index 3 is the latest version so our SQLite transaction will read page 2 from WAL entry 3.
Astute readers may notice that we can have collisions across multiple pages. What happens if page 2 & page 543 in a database compute the same slot? SQLite will double check each entry in the page numbers list to make sure it’s the actual page we’re looking for and it will discard any others automatically.
Choosing a journaling strategy
While there are always trade-offs between design choices, the vast majority of applications will benefit from WAL mode. The SQLite web site helpfully lists some edge cases where the rollback journal would be a better choice such as when using multi-database transactions. However, those situations are rare for most applications.
Now that you understand how data is stored and transactions are safely handled, we’ll take a look at the query side of SQLite in our next post which will cover the SQLite Virtual Machine.