

We’re Fly.io, a security bearer token company with a public cloud problem. You can read more about what our platform does (Docker container goes in, virtual machine in Singapore comes out), but this is just an engineering deep-dive into how we make our security tokens work. It’s a tokens nerd post.
1
We’ve spent too much time talking about security tokens, and about Macaroon tokens in particular. Writing another Macaroon treatise was not on my calendar. But we’re in the process of handing off our internal Macaroon project to a new internal owner, and in the process of truing up our operations manuals for these systems, I found myself in the position of writing a giant post about them. So, why not share?
Can I sum up Macaroons in a short paragraph? Macaroon tokens are bearer tokens (like JWTs) that use a cute chained-HMAC construction that allows an end-user to take any existing token they have and scope it down, all on their own. You can minimize your token before every API operation so that you’re only ever transmitting the least amount of privilege needed for what you’re actually doing, even if the token you were issued was an admin token. And they have a user-serviceable plug-in interface! You’ll have to read the earlier post to learn more about that.
Yes, probably, we are.
A couple years in to being the Internet’s largest user of Macaroons, I can report (as many predicted) that for our users, the cool things about Macaroons are a mixed bag in practice. It’s very neat that users can edit their own tokens, or even email them to partners without worrying too much. But users don’t really take advantage of token features.
But I’m still happy we did this, because Macaroon quirks have given us a bunch of unexpected wins in our infrastructure. Our internal token system has turned out to be one of the nicer parts of our platform. Here’s why.
2
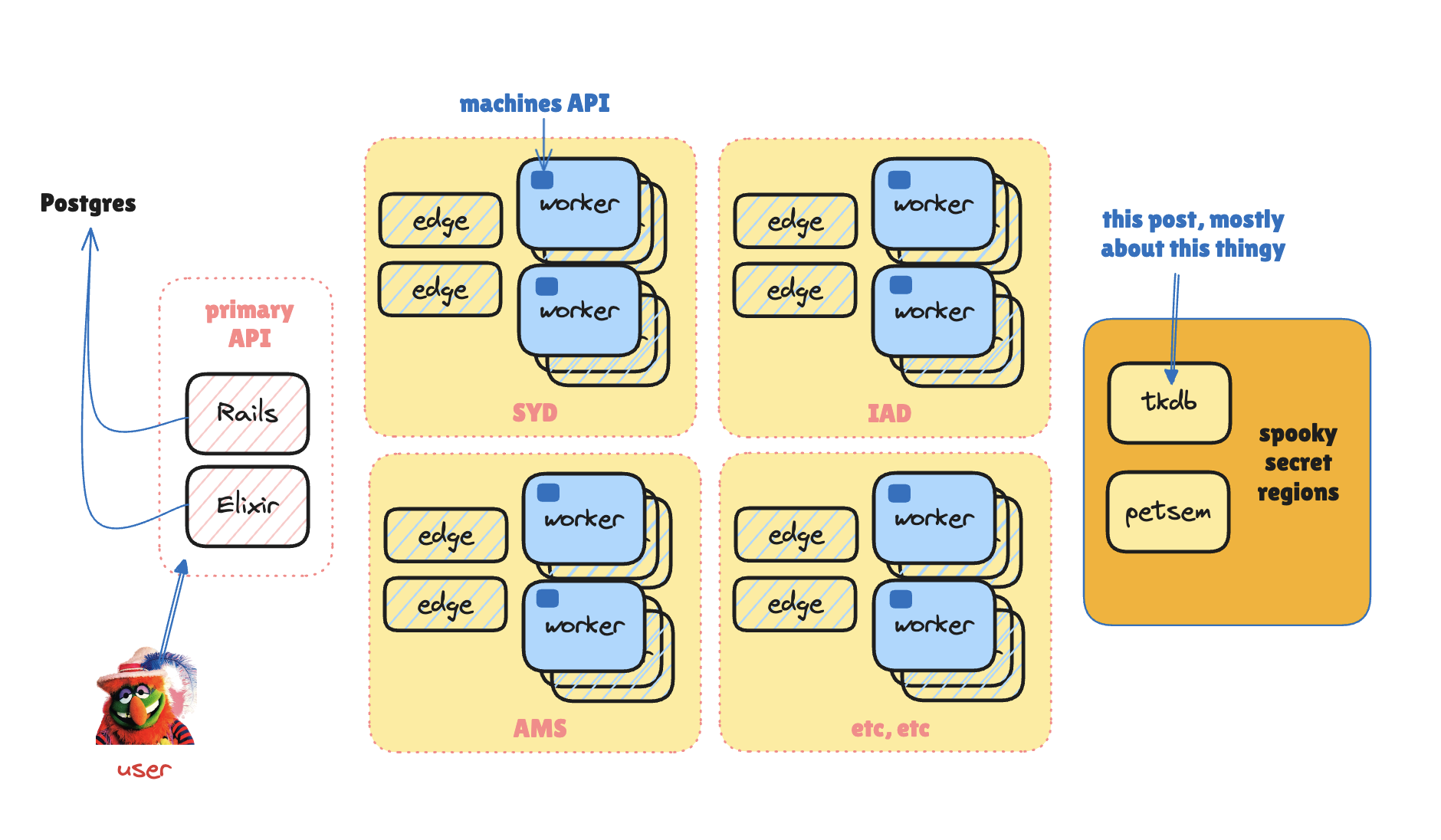
As an operator, the most important thing to know about Macaroons is that they’re online-stateful; you need a database somewhere. A Macaroon token starts with a random field (a nonce) and the first thing you do when verifying a token is to look that nonce up in a database. So one of the most important details of a Macaroon implementation is where that database lives.
I can tell you one place we’re not OK with it living: in our primary API cluster.
There’s several reasons for that. Some of them are about scalability and reliability: far and away the most common failure mode of an outage on our platform is “deploys are broken”, and those failures are usually caused by API instability. It would not be OK if “deploys are broken” transitively meant “deployed apps can’t use security tokens”. But the biggest reason is security: root secrets for Macaroon tokens are hazmat, and a basic rule of thumb in secure design is: keep hazmat away from complicated code.
So we created a deliberately simple system to manage token data. It’s called tkdb.
LiteFS: primary/replica distributed SQLite; Litestream: PITR SQLite replication to object storage; both work with unmodified SQLite libraries.
tkdb is about 5000 lines of Go code that manages a SQLite database that is in turn managed by LiteFS and Litestream. It runs on isolated hardware (in the US, Europe, and Australia) and records in the database are encrypted with an injected secret. LiteFS gives us subsecond replication from our US primary to EU and AU, allows us to shift the primary to a different region, and gives us point-in-time recovery of the database.
We’ve been running Macaroons for a couple years now, and the entire tkdb database is just a couple dozen megs large. Most of that data isn’t real. A full PITR recovery of the database takes just seconds. We use SQLite for a lot of our infrastructure, and this is one of the very few well-behaved databases we have.
That’s in large part a consequence of the design of Macaroons. There’s actually not much for us to store! The most complicated possible Macaroon still chains up to a single root key (we generate a key per Fly.io “organization”; you don’t share keys with your neighbors), and everything that complicates that Macaroon happens “offline”. We take advantage of “attenuation” far more than our users do.
The result is that database writes are relatively rare and very simple: we just need to record an HMAC key when Fly.io organizations are created (that is, roughly, when people sign up for the service and actually do a deploy). That, and revocation lists (more on that later), which make up most of the data.
3
Talking to tkdb from the rest of our platform is complicated, for historical reasons.
NATS is fine, we just don’t really need it.
Ben Toews is responsible for most of the good things about this implementation. When he inherited the v0 Macaroons code from me, we were in the middle of a weird love affair with NATS, the messaging system. So tkdb exported an RPC API over NATS messages.
Our product security team can’t trust NATS (it’s not our code). That means a vulnerability in NATS can’t result in us losing control of all our tokens, or allow attackers to spoof authentication. Which in turn means you can’t run a plaintext RPC protocol for tkdb over NATS; attackers would just spoof “yes this token is fine” messages.
I highly recommend implementing Noise; the spec is kind of a joy in a way you can’t appreciate until you use it, and it’s educational.
But you can’t just run TLS over NATS; NATS is a message bus, not a streaming secure channel. So I did the hipster thing and implemented Noise. We export a “verification” API, and a “signing” API for minting new tokens. Verification uses Noise_IK (which works like normal TLS) — anybody can verify, but everyone needs to prove they’re talking to the real tkdb. Signing uses Noise_KK (which works like mTLS) — only a few components in our system can mint tokens, and they get a special client key.
A little over a year ago, JP led an effort to replace NATS with HTTP, which is how you talk to tkdb today. Out of laziness, we kept the Noise stuff, which means the interface to tkdb is now HTTP/Noise. This is a design smell, but the security model is nice: across many thousands of machines, there are only a handful with the cryptographic material needed to mint a new Macaroon token. Neat!
tkdb is a Fly App (albeit deployed in special Fly-only isolated regions). Our infrastructure talks to it over “FlyCast”, which is our internal Anycast service. If you’re in Singapore, you’re probably get routed to the Australian tkdb. If Australia falls over, you’ll get routed to the closest backup. The proxy that implements FlyCast is smart, as is the tkdb client library, which will do exponential backoff retry transparently.
Even with all that, we don’t like that Macaroon token verification is “online”. When you operate a global public cloud one of the first thing you learn is that the global Internet sucks. Connectivity breaks all the time, and we’re paranoid about it. It’s painful for us that token verification can imply transoceanic links. Lovecraft was right about the oceans! Stay away!
Our solution to this is caching. Macaroons, as it turns out, cache beautifully. That’s because once you’ve seen and verified a Macaroon, you have enough information to verify any more-specific Macaroon that descends from it; that’s a property of their chaining HMAC construction. Our client libraries cache verifications, and the cache ratio for verification is over 98%.
4
Revocation isn’t a corner case. It can’t be an afterthought. We’re potentially revoking tokens any time a user logs out. If that doesn’t work reliably, you wind up with “cosmetic logout”, which is a real vulnerability. When we kill a token, it needs to stay dead.
Our revocation system is simple. It’s this table:
CREATE TABLE IF NOT EXISTS blacklist (
nonce BLOB NOT NULL UNIQUE,
required_until DATETIME,
created_at DATETIME DEFAULT CURRENT_TIMESTAMP
);
When we need a token to be dead, we have our primary API do a call to the tkdb “signing” RPC service for revoke. revoke takes the random nonce from the beginning of the Macaroon, discarding the rest, and adds it to the blacklist. Every Macaroon in the lineage of that nonce is now dead; we check the blacklist before verifying tokens.
The obvious challenge here is caching; over 98% of our validation requests never hit tkdb. We certainly don’t want to propagate the blacklist database to 35 regions around the globe.
Instead, the tkdb “verification” API exports an endpoint that provides a feed of revocation notifications. Our client library “subscribes” to this API (really, it just polls). Macaroons are revoked regularly (but not constantly), and when that happens, clients notice and prune their caches.
If clients lose connectivity to tkdb, past some threshold interval, they just dump their entire cache, forcing verification to happen at tkdb.
5
A place where we’ve gotten a lot of internal mileage out of Macaroon features is service tokens. Service tokens are tokens used by code, rather than humans; almost always, a service token is something that is stored alongside running application code.
An important detail of Fly.io’s Macaroons is the distinction between a “permissions” token and an “authentication” token. Macaroons by themselves express authorization, not authentication.
That’s a useful constraint, and we want to honor it. By requiring a separate token for authentication, we minimize the impact of having the permissions token stolen; you can’t use it without authentication, so really it’s just like a mobile signed IAM policy expression. Neat!
The way we express authentication is with a third-party caveat (see the old post for details). Your main Fly.io Macaroon will have a caveat saying “this token is only valid if accompanied by the discharge token for a user in your organization from our authentication system”. Our authentication system does the login dance and issues those discharges.
This is exactly what you want for user tokens and not at all what you want for a service token: we don’t want running code to store those authenticator tokens, because they’re hazardous.
The solution we came up with for service tokens is simple: tkdb exports an API that uses its access to token secrets to strip off the third-party authentication caveat. To call into that API, you have to present a valid discharging authentication token; that is, you have to prove you could already have done whatever the token said. tkdb returns a new token with all the previous caveats, minus the expiration (you don’t usually want service tokens to expire).
OK, so we’ve managed to transform a tuple (unscary-token, scary-token) into the new tuple (scary-token). Not so impressive. But hold on: the recipient of scary-token can attenuate it further: we can lock it to a particular instance of flyd, or to a particular Fly Machine. Which means exfiltrating it doesn’t do you any good; to use it, you have to control the environment it’s intended to be used in.
The net result of this scheme is that a compromised physical host will only give you access to tokens that have been used on that worker, which is a very nice property. Another way to look at it: every token used in production is traceable in some way to a valid token a user submitted. Neat!
All the cool spooky secret store names were taken.
We do a similar dance to with Pet Semetary, our internal Vault replacement. Petsem manages user secrets for applications, such as Postgres connection strings. Petsem is its own Macaroon authority (it issues its own Macaroons with its own permissions system), and to do something with a secret, you need one of those Petsem-minted Macaroon.
Our primary API servers field requests from users to set secrets for their apps. So the API has a Macaroon that allows secrets writes. But it doesn’t allow reads: there’s no API call to dump your secrets, because our API servers don’t have that privilege. So far, so good.
But when we boot up a Fly Machine, we need to inject the appropriate user secrets into it at boot; something needs a Macaroon that can read secrets. That “something” is flyd, our orchestrator, which runs on every worker server in our fleet.
Clearly, we can’t give every flyd a Macaroon that reads every user’s secret. Most users will never deploy anything on any given worker, and we can’t have a security model that collapses down to “every worker is equally privileged”.
Instead, the “read secret” Macaroon that flyd gets has a third-party caveat attached to it, which is dischargeable only by talking to tkdb and proving (with normal Macaroon tokens) that you have permissions for the org whose secrets you want to read. Once again, access is traceable to an end-user action, and minimized across our fleet. Neat!
6
Our token systems have some of the best telemetry in the whole platform.
Most of that is down to OpenTelemetry and Honeycomb. From the moment a request hits our API server through the moment tkdb responds to it, oTel context propagation gives us a single narrative about what’s happening.
I was a skeptic about oTel. It’s really, really expensive. And, not to put too fine a point on it, oTel really cruds up our code. Once, I was an “80% of the value of tracing, we can get from logs and metrics” person. But I was wrong.
Errors in our token system are rare. Usually, they’re just early indications of network instability, and between caching and FlyCast, we mostly don’t have to care about those alerts. When we do, it’s because something has gone so sideways that we’d have to care anyways. The tkdb code is remarkably stable and there hasn’t been an incident intervention with our token system in over a year.
Past oTel, and the standard logging and Prometheus metrics every Fly App gets for free, we also have a complete audit trail for token operations, in a permanently retained OpenSearch cluster index. Since virtually all the operations that happen on our platform are mediated by Macaroons, this audit trail is itself pretty powerful.
7
So, that’s pretty much it. The moral of the story for us is, Macaroons have a lot of neat features, our users mostly don’t care about them — that may even be a good thing — but we get a lot of use out of them internally.
As an engineering culture, we’re allergic to “microservices”, and we flinched a bit at the prospect of adding a specific service just to manage tokens. But it’s pulled its weight, and not added really any drama at all. We have at this point a second dedicated security service (Petsem), and even though they sort of rhyme with each other, we’ve got no plans to merge them. Rule #10 and all that.
Oh, and a total victory for LiteFS, Litestream, and infrastructure SQLite. Which, after managing an infrastructure SQLite project that routinely ballooned to tens of gigabytes and occasionally threatened service outages, is lovely to see.
Macaroons! If you’d asked us a year ago, we’d have said the jury was still out on whether they were a good move. But then Ben Toews spent a year making them awesome, and so they are. Most of the code is open source!