

Fly.io runs apps close to users around the world, by taking containers and upgrading them to full-fledged virtual machines running on our own hardware around the world. Sometimes those containers run SQLite and we make that easy too. Give us a whirl and get up and running quickly.
When database vendors recite their long list of features, they never enumerate “doesn’t lose your data” as one of those features. It’s just assumed. That’s what a database is supposed to do. However, in reality, the best database vendors tell you exactly how their database will lose your data.
I’ve written before about how SQLite stores your data. In order not to lose any of it when a transaction goes wrong, SQLite implements a journal. It has two different modes: the rollback journal & the write-ahead log. Today we’re diving into the rollback journal: what it is, how it works, and when to use it.
How to lose your data
To understand why you need a database journal, let’s look at what happens without one. In the last post, we talked about how SQLite is split up into 4KB chunks called “pages”. Any time you make a change—even a 1 byte change—SQLite will write a full 4KB page.
If you tried to overwrite a page in your database file directly, it would work fine 99% of the time. However, that 1% of the time is catastrophic. If your server suddenly shut down halfway through a page write then you’ll end up with a corrupted database.
The database needs to ensure that all page writes for a transaction either get written or don’t. No halfsies. This is called atomicity.
But that’s not all. If another process is querying the database, it’ll have no consistent view of the data since you’re overwriting pages willy-nilly. The database needs to ensure each transaction has a snapshot view of the database for its entire duration. This is called isolation.
Finally, we need to make sure bytes actually get flushed to disk. This part is called durability.
Those make up 3 of the 4 letters of the ACID transactional guarantee that every database blog post is required to mention. The “C” stands for consistency but that doesn’t involve the rollback journal so we’ll skip that.
All for one, or none at all
Every textbook definition of transactions involves a bank transfer where someone withdraws money from one account and deposits in another. Both actions must happen or neither must happen.
This example gets trotted out because atomicity is so unusual in the physical world that it’s hard to find anything else that’s as intuitive to understand.
But it turns out that atomicity doesn’t “just happen” in databases either. It’s all smoke and mirrors. So let’s use a better example that involves our favorite topic: sandwiches.
Building a sandwich
When you go to a sandwich shop, you walk up to the counter, announce your order, and you get a tasty sandwich in hand a short time after. To you, the consumer, this is atomic. If you order a ham-and-cheese sandwich, you won’t receive just a slice of ham or two pieces of dry bread. You either get a sandwich or you don’t.
But behind the counter, there are multiple steps involved: grab the bread, add the ham, add the cheese, hand it to the customer. If the sandwich maker gets to the cheese step and realizes they’re out of cheese, they can tell you they can’t make the sandwich and then put the ham and bread back where they found it. The internal state of the sandwich shop is restored to how it was before the order started.
The rollback journal is similar. It records the state of the database before any changes are made. If anything goes wrong before we get to the end, we can use the journal to put the database back in its previous state.
Our first transaction
Let’s start our first transaction by creating a table in a sandwiches.db database:
CREATE TABLE sandwiches (
id INTEGER PRIMARY KEY,
name TEXT
);
SQLite starts by creating a sandwiches.db-journal file next to our sandwiches.db database file and writing a journal header:
00000000 00000000 00000000 f65ddb21 00000000 00000200 00001000
The first 12 bytes are filled with zeros but they’ll be overwritten at the end of our transaction so let’s skip them for now.
The value 0xf65ddb21 is called a nonce and it’s a randomly generated number that we’ll use to compute checksums for our entries in the journal. SQLite has some journal modes where it’ll overwrite the journal instead of delete it so the checksums help SQLite know when its working with contiguous set of entries and not reading old entries left behind from previous transactions.
Next, we have 0x00000000 which is the size of the database before the transaction started. Since this is the first transaction, our database was empty before the transaction.
Then we specify the sector size of 0x00000200 (or 512). A disk sector is the smallest unit we typically work with for disk drives and SQLite keeps the journal header on its own sector. It does this because journal header is later rewritten and we don’t want to accidentally corrupt one of our pages if a sector write fails.
Finally, we have 0x00001000 (or 4,096) which is the page size for our database, in bytes.
SQLite can now freely write changes to the database file while knowing that it has written down the state of the database from before the transaction started.
When you go to commit the changes, SQLite will rewrite the first 12 bytes of the journal header with two new fields: the magic number & the number of page entries in the journal.
d9d505f9 20a163d7 00000000
The “magic number” is a ridiculous name for a constant value that is written to the beginning of a file to indicate its file type. For journal files, this magic number is d9d505f9 20a163d7. We don’t have any page entries since our database was empty so the page count stays as zeros.
Next, we’ll sync the journal to disk to make sure we don’t lose it.
The final step that ends the commit is when SQLite deletes the file. If any of the previous steps fail then SQLite can use the rollback journal to revert the state of the database. Just like with your ham-and-cheese, the transaction doesn’t happen until you have a sandwich in your hand.
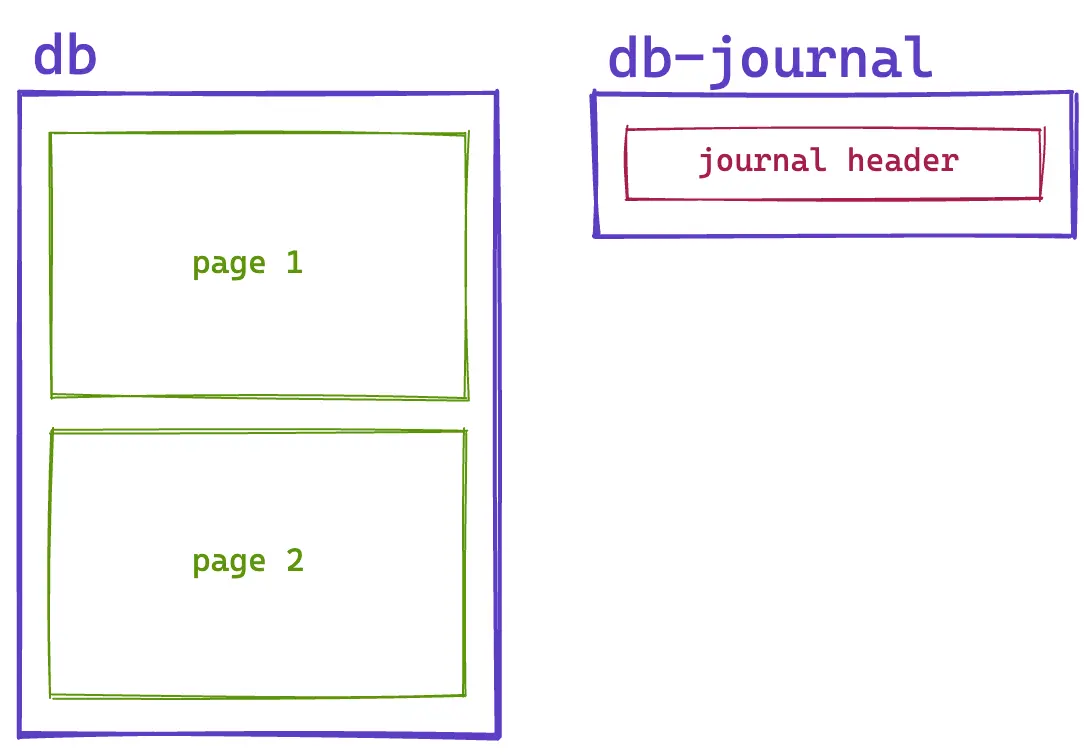
Copying out to the journal
Now let’s see how the journal works with an existing database. Our first transaction left us with a 2-page database. The first page holds our database header and some metadata about our schema. The second page is an empty leaf page for our sandwiches table.
We’ll insert our sandwich into our table:
BEGIN;
INSERT INTO sandwiches (name) VALUES ('ham and cheese');
This will create a new journal with the following header:
00000000 00000000 00000000 0600399E 00000002 00000200 00001000
It looks similar to before but we have a new randomly-generated nonce (0x0600399e) and our database size before the transaction is now 0x00000002 pages instead of zero.
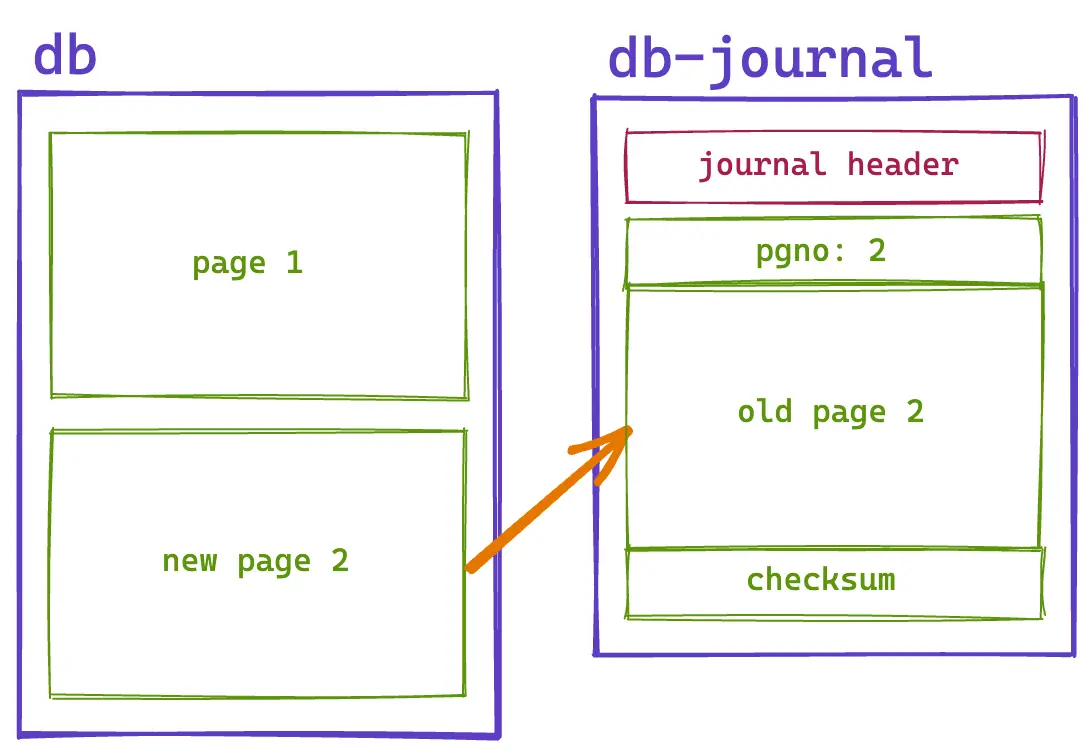
Since our transaction is updating the leaf page, SQLite needs to copy out the original version of the page to the journal as a page record. The journal page records are comprised of 3 fields.
First, we have the page number to indicate that we’re updating page 2:
00000002
Then it’s followed by a copy of the 4,096 bytes that were in the page before the transaction started. Finally, it computes a 32-bit checksum on the data in the page:
0600399e
Interestingly, the checksum is only calculated on a very sparse number of bytes in the page and is primarily meant to guard against incomplete writes. Since SQLite 3.0.0 dates back to 2004 and it works on minimal hardware, reducing any overhead can be critical. You can see the evolution of computing power as the WAL mode, which was introduced in 2010, checksums the entire page.
With our original copy of the page in the journal, we can update our copy in the main database file without having to re-copy the page. We can add a second sandwich to our transaction and SQLite will only update the main database file:
INSERT INTO sandwiches (name) VALUES ('cheesesteak');
The database and journal end up looking like this:
When sandwiches go bad
Back to our sandwich shop example, let’s say there is a catastrophic sandwich event that occurs in the middle of your order. Perhaps your sandwich artist couldn’t stand to make one more ham-and-cheese sandwich and abruptly quit.
So our shop owner subs out a new employee to replace the old one so the sandwich production can continue. But how do we deal with the in-process sandwich? The new employee could try to finish the sandwich but maybe the customer gave specific instructions to the old employee. When you’re dealing with something as critical as lunch, it’s best to start over and do it right.
When SQLite encounters a failure scenario, such as an application dying or a server losing power, it needs to go through a process called “recovery”. For a rollback journal, this is simple. We can walk through our journal page records and copy each page back into the main database file. At the end, we truncate our main database file to the size specified in the journal header.
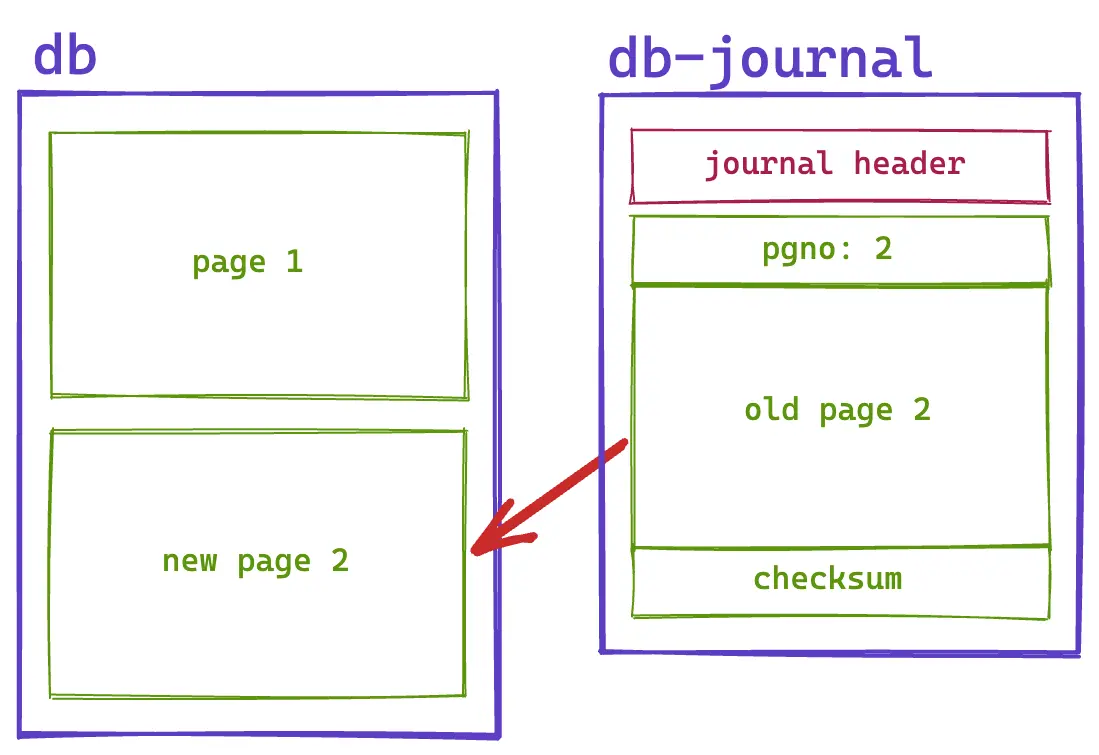
Rollback journals are even resistant to failures during their own recovery. If your server crashes midway through a recovery process, SQLite will simply start the recovery process from the beginning of the journal file.
The procedure is idempotent and is not considered complete until the pages copied back are synced to disk and the journal file is deleted. For example, let’s say we’d only copied half of page 2 in our diagram from the journal back to the database file and then our server crashed. When we restart, we still have our journal file in place and we can simply try copying that page again.
Keeping track of our ingredients
Our sandwich shop owner begins to suspect that employees are skimming pickles off the line and decides to hire folks to inventory ingredients periodically. However, the owner quickly realizes that the inventory numbers are off because the inventory specialists are trying to count ingredients while sandwich makers are taking those same ingredients to put into sandwiches.
To fix this, the owner decides that the store must be locked while a sandwich is being made. However, when a sandwich isn’t being made, any number of inventory specialists can come in and count ingredients.
This is how it works in SQLite when using the rollback journal. Any number of read-only transactions can occur at the same time. However, when we start a write transaction then we need to wait for the readers to finish and block all new readers until the write is done.
This makes sense now that you know that we’re changing the main database file during a write transaction. We’d have no way to give read transactions a snapshot view of the database if we’re updating the same underlying data.
Read/write locks on the file system
Since SQLite allows multiple processes to access it, it needs to perform locking at the file system level. There are 3 lock bytes that are used to implement the read/write lock at the file system level:
SHARED- held by read transactions, prevents writers from startingRESERVED- held by the write transactionPENDING- held by the write transaction to prevent readers from starting
When a read transaction starts, it checks the PENDING lock first to ensure a writer is not inside a write transaction or that a writer is not waiting to start a transaction. If the reader can obtain the PENDING lock then it obtains a shared lock on the SHARED lock byte and holds it until the end of the transaction.
For write transactions, it first obtains an exclusive lock on the PENDING lock byte to prevent new read transactions from starting. It then tries to obtain an exclusive lock on the SHARED lock byte to wait for in-process read transactions to finish. Finally, it obtains an exclusive lock on the RESERVED lock byte to indicate that a write transaction is in-process.
This series of steps ensure that only one write transaction is in effect at any time and that new readers won’t block it.
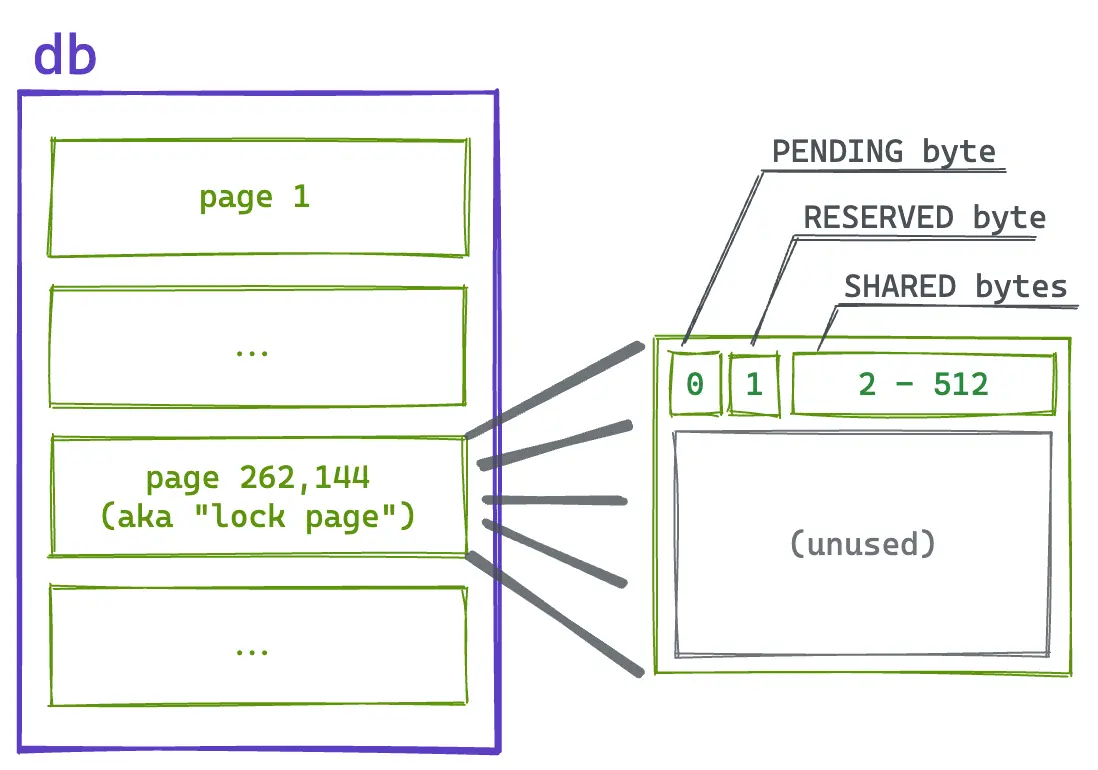
Locks are located on a page at the 1GB position in the database file and this page is unusable by SQLite as some Windows versions use mandatory locks instead of advisory locks. If a database is smaller than 1GB, this page is never allocated and only exists within the operating system’s lock accounting system.
Within the lock page, a byte is used for the PENDING lock and another byte for the RESERVED lock. After that, 510 bytes are used for the SHARED lock. A byte range is used here to accommodate older Windows versions with mandatory locks. In those cases, a randomly chosen byte is locked by a client within that range. On Unix, the entire range is locked using fctnl() and F_RDLCK.
How to improve on journaling
The rollback journal is a simple trick to simulate atomicity and isolation and to provide durability to a database. Simple tricks are the best kind of tricks when you write a database so it’s a great place to start.
But it certainly has its trade-offs. Kicking out all other transactions whenever you need to write something can become a bottleneck for many applications that have concurrent users. When people say that SQLite doesn’t scale, it’s typically because they used the rollback journal.
However, SQLite continued to improve and eventually introduced the write-ahead log (WAL) journaling mode and even the wal2 journaling mode. These provide significantly better support for concurrent readers.
This means that our inventory specialists in our example could each have a point-in-time view of all the ingredients—even while the sandwich maker continues to make sandwiches! We’ll get into how this works in our next post on WAL mode.