

With Fly.io, you can get your app running globally in a matter of minutes, and with LiteFS, you can run SQLite alongside your app! Now we’re introducing LiteFS Cloud: managed backups and point-in-time restores for LiteFS. Try it out for yourself!
My favorite part about building tools is discovering their unintended uses. It’s like starting to write a murder mystery book but you have no idea who the killer is!
History is filled with examples of these accidental discoveries: WD-40 was originally used to protect ICBMs from rust and now it fixes your squeaky doorknob. Bubble wrap was originally sold as wallpaper and now it protects your Amazon packages.
When we started writing LiteFS, a distributed SQLite database, we thought it would be used to distribute data geographically so users in, say, Bucharest see response times as fast as users in San Jose. And for the most part, that’s what LiteFS users are doing.
But we discovered another unexpected use: replacing the API layer between services with SQLite databases.
How it started
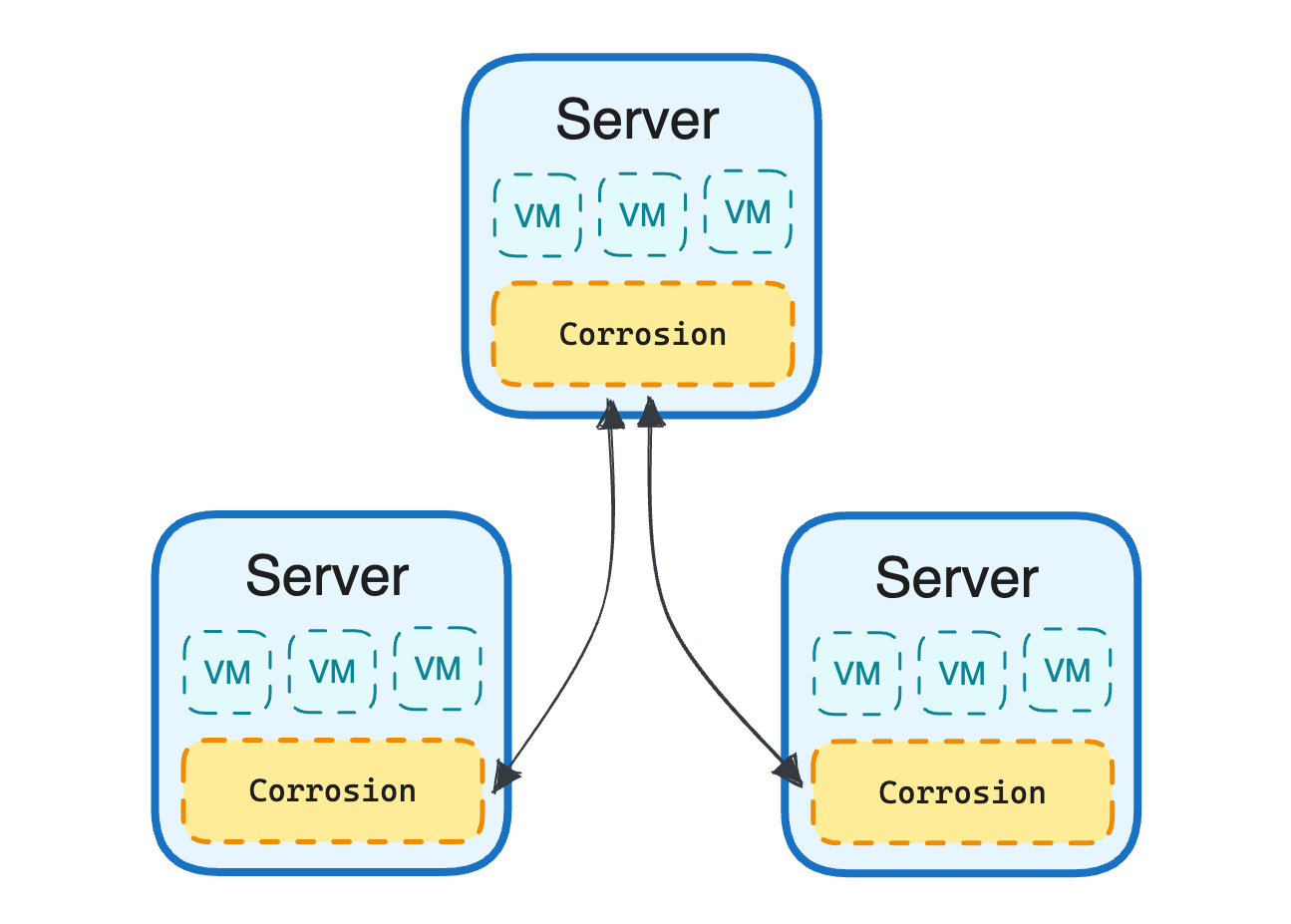
In the early days of LiteFS development, we wanted to find a real-world test bed for our tool so we could smoke out any bugs that we didn’t find during automated tests. Part of our existing infrastructure is a program called Corrosion that gossips state between all our servers. Corrosion tracks VM statuses, health checks, and a plethora of other information for each server and communicates this info with other servers so they can make intelligent decisions about request routing and VM placement. Corrosion keeps a fast, local copy of all this data in a SQLite database.
So we set up a Corrosion instance that also ran on top of LiteFS. This helped root out some bugs but we also found another use for it: making Corrosion accessible to our internal services.
Shipping the kitchen sink
The typical approach to making data available between services is to spend weeks designing an API and then building a service around it. Your API design needs to take into account the different use cases of each consuming service so that it can deliver the data it needs efficiently. You don’t want your clients making a dozen API calls for every request!
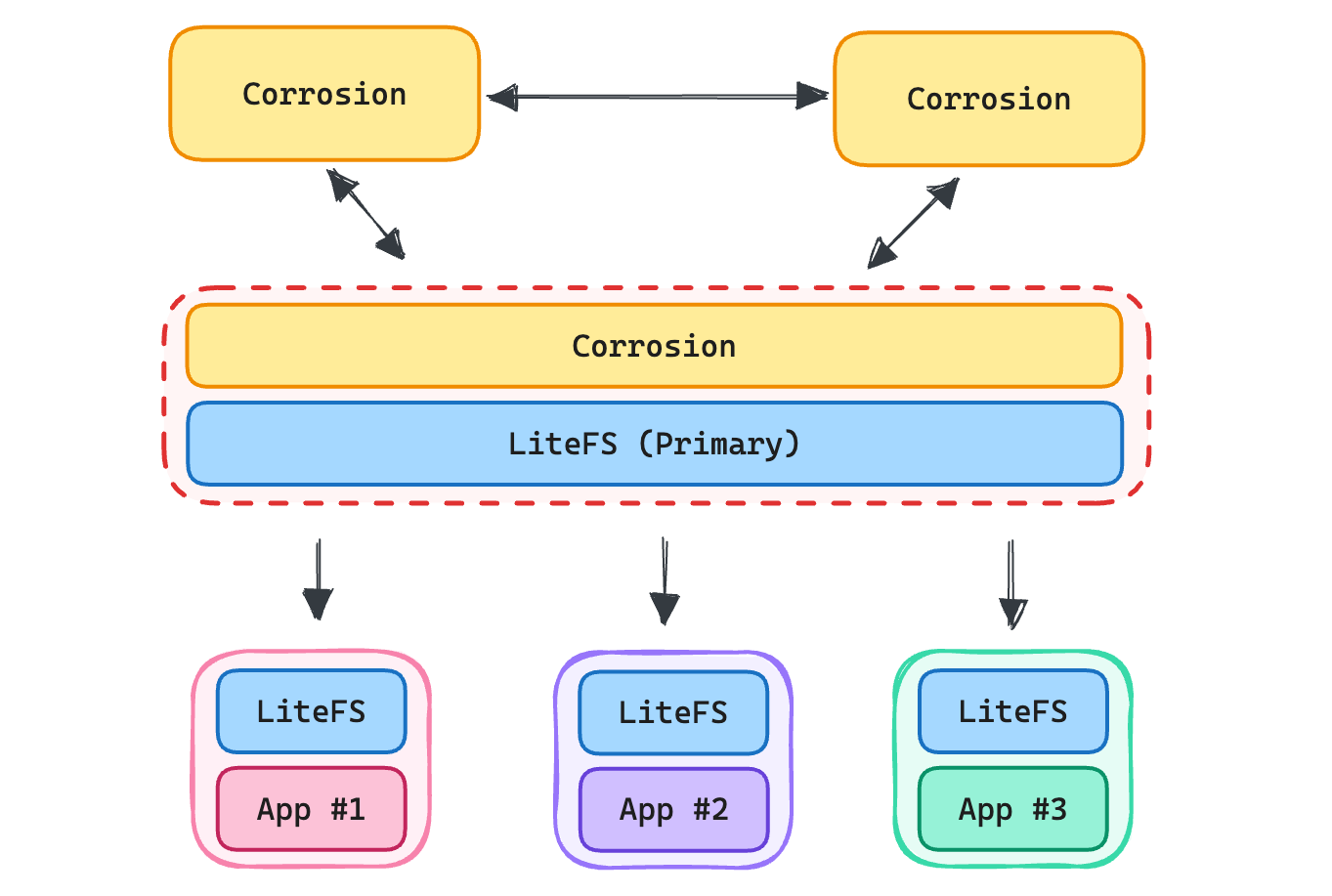
A different approach is to skip the API design entirely and just ship the entire database to your client. You don’t need to consider the consuming service’s access patterns as they can use vanilla SQL to query and join whatever data their heart desires. That’s what we did using LiteFS.
While we could have set up each downstream service as a Corrosion node, gossip protocols can be chatty and we really just needed a one-way stream of updates. Setting up a read-only LiteFS instance for a new service is simple—it just needs the hostname of the upstream primary node to connect to:
lease:
type: "static"
candidate: false
advertise-url: "http://corrosion-bridge:20202
And voila! You have a full, read-only copy of the database on your app.
Moving compute to the client
API design is notoriously difficult as it’s hard to know what your consuming services will need. Query languages such as GraphQL have even been invented for this specific problem!
However, GraphQL has its own limitations. It’s good for fetching raw data but it lacks built-in aggregation & advanced querying capabilities like windowing. GraphQL is typically layered on top of an existing relational database that uses SQL. So why not just use SQL?
Additionally, performing queries on your service means that you need to handle multiple tenants competing for compute resources. Managing these tenants involves rate limiting and query timeouts so that no one client consumes all the resources.
By pushing a read-only copy of the database to clients, these restrictions aren’t a concern anymore. A tenant can use 100% of its CPU for hours if it wants to. It won’t adversely affect any other tenant because the query is running on its own hardware.
So what’s the downside?
There’s always trade-offs with any technology and shipping read-only replicas is no different. One obvious limitation of read-only replicas is that they’re read-only. If your clients need to update data, they’ll still need an API for those mutations.
A less obvious downside is that the contract for a database can be less strict than an API. One benefit to an API layer is that you can change the underlying database structure but still massage data to look the same to clients. When you’re shipping the raw database, that becomes more difficult. Fortunately, many database changes, such as adding columns to a table, are backwards compatible so clients don’t need to change their code. Database views are also a great way to reshape data so it stays consistent—even when the underlying tables change.
Finally, shipping a database limits your ability to restrict access to data. If you have a multi-tenant database, you can’t ship that database without the client seeing all the data. One workaround for this is to use a database per tenant. SQLite databases are lightweight since they are just files on disk. This also has the added benefit of preventing queries in your application from accidentally fetching data across tenants.
Where do we take this next?
While this approach has worked well for some internal tooling, how does this look in the broader world of software? APIs are likely stick around for the foreseeable future so providing read-only database replicas make sense for specific use cases where those APIs aren’t a great fit.
Imagine being able to query all your Stripe data or your GitHub data from a local database. You could join that data on to your own dataset and perform fast queries on your own hardware.
While companies such as Stripe or GitHub likely colocate their tenant data into one database, many companies run an event bus using tools like Kafka which could allow them to generate per-tenant SQLite databases to then stream to customers.
Pushing queries out to the end user has huge benefits for both the data provider & the data consumer in terms of flexibility and power.