

In this post we use Fly Machines to implement lightweight background jobs for a Python web application. Check it out: you can be up and running on Fly.io in just minutes.
Last year, while working in what was my day job at the time (before I joined Fly.io!), we had just developed a new internal tool to help an adjacent team with their work. This adjacent team wrote technical content, and they had a lot of issues stemming from differences in library and language versions in the team members’ local environments as compared to our production environment.
There are a lot of possible solutions to this problem, but because of the unique needs and skillset of this team, we decided to build an app for them to work in, and allow them to just get rid of their local environment entirely. This way, we could ensure that all the versions were exactly as expected, and over time we could also add more assistive features.
At the start, this was a super-hastily-thrown-together, barely an MVP tool that kinda sorta met the internal users’ needs most of the time. The first version was only good enough because their previous workflow was just so awful — it was difficult for us to do worse.
One thing our new app needed to do, was build and install libraries (the same ones our teammates had been installing locally), and we needed to rebuild them regularly (think, when a user clicks a “Build” button in the app).
Initially, we simply implemented these builds in the backend directly. This worked great for a little while, and it was nice to only have to deploy one thing. But then we discovered that (1) for some edge cases, our builds were very slow (occasionally over 30 minutes — far too slow for the HTTP request cycle…), and (2) some builds took a lot of resources, so occasionally, even after over-provisioning, if two builds came in at once, our backend got killed (and the builds never completed).
Based on this less-than-awesome experience, it became clear to us that we needed background jobs!
We ended up configuring Celery, as one does (when one is a Python developer anyway). However, this wasn’t as pain-free as it could have been. There’s some significant configuration required, and Celery was overkill for our very simple use case.
Plus – those expensive builds? We needed to have a worker (or several workers) available to run them any time, even though we only had a handful of team members using the tool, so most of the time the worker was idle. We were paying for resources we weren’t using most of the time — not at all awesome for a bootstrapped startup!
So, how could we have implemented super simple background jobs, and avoid paying for resources we didn’t need?
Well, it turns out that it’s really pretty easy to implement simple background jobs using Fly Machines! I’ll show you how.
How it works
First some background. Fly Machines are lightweight VMs based on Firecracker that start up super fast (you can read more details about Machines in our Machines documentation). They also have a convenient and simple API, making them easy to start, stop, and interact with from your code.
For the purposes of this post, we’ll be building a demo app - a super minimal Flask web application which sends email in a background job (full code available here). You can also try out the application at darla-send-email.fly.dev. Note: for demonstration purposes, the application I’ve deployed uses the dummy_send_email function, which doesn’t actually send an email! You can also deploy your own version with real Mailjet credentials, though.
So, here’s how our implementation works from a high level:
- The web application (or a library the web app uses) writes some job parameters to Redis
- The web application calls the Fly Machines API to start a new machine, adding an env variable to tell the worker which Redis key to load job params from
- When the worker starts, it reads the job params from Redis
- The worker does its magic! ✨
- The worker writes results to Redis
- The web app retrieves the results!
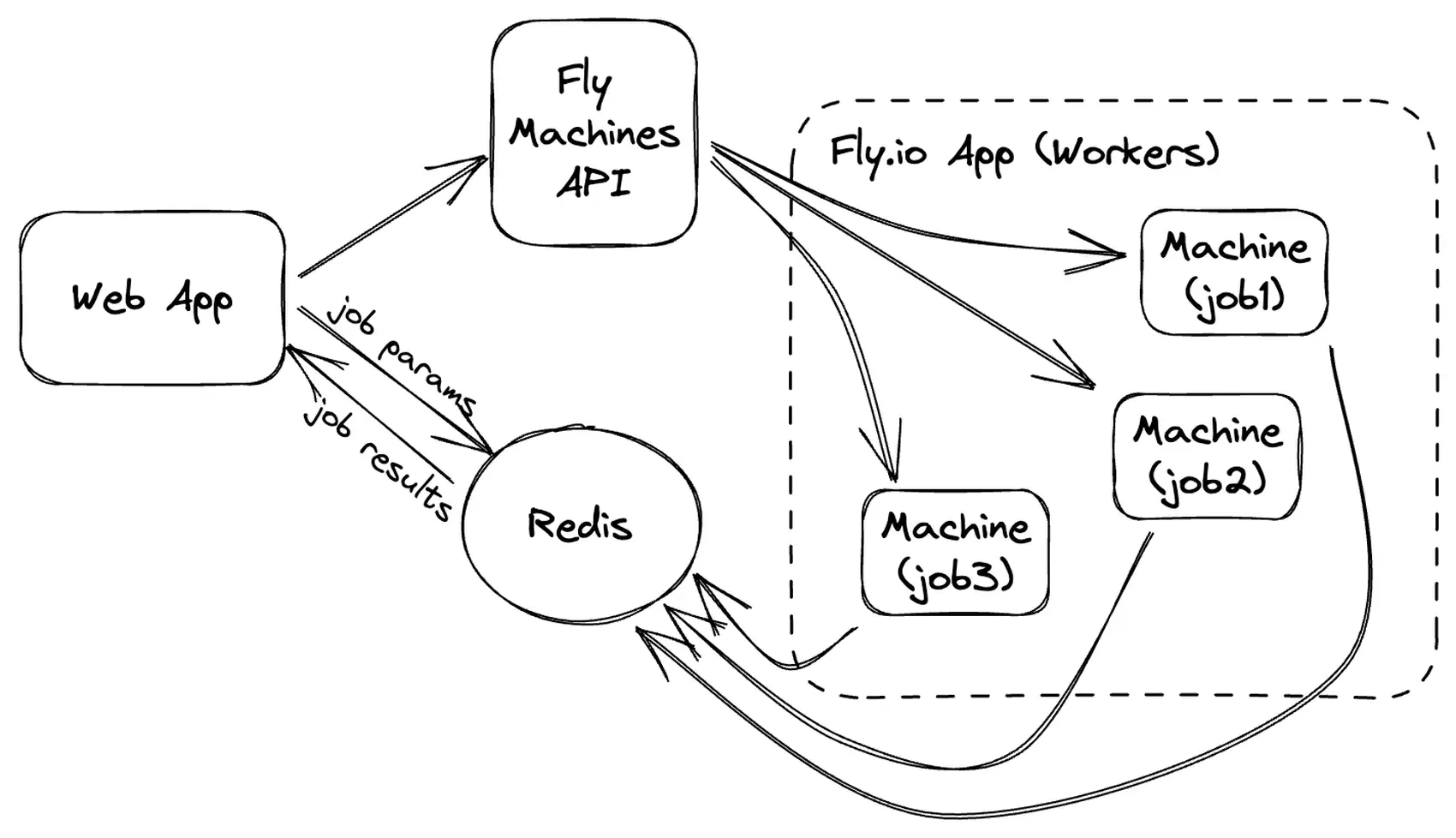
One really cool thing about this implementation is that you only pay for worker resources when your workers are actually, you know, doing work. For infrequent, expensive background jobs, this can make a huge difference in costs!
Before we get into the code, we’ll need to set up a few bits of infrastructure. Let’s check how that’s done.
Infrastructure setup
I’ll assume you’ve already set up your Fly.io account and installed the flyctl commandline tool. If you haven’t done that yet, follow these instructions to install flyctl, sign up, log in to fly.io, and then come back here!
After you have your Fly.io account set up and flyctl installed locally, you’ll need to create two pieces of infrastructure: a Fly.io App, which the Machines that run the background jobs will belong to, and a Redis instance, which we’ll use to communicate between the web application and the background job Machines.
Create an app
Fly.io Machines need to be created in an app, so we’ll need to create an app.
fly apps create my-machine-tasks # name your app something appropriate!
Warning: app names are unique across all Fly.io users, so you’ll need to pick something unique. You can also call fly apps create without an app name, and let it generate one for you, if you’re stuck.
Create an Upstash Redis instance
fly redis create
Take note of the Redis url that’s printed after creation. If you forget it, you can see it again using fly redis status.
The worker code
First, let’s take a look at the code that we’ll run on the Machine:
def run_task():
redis_client = redis.from_url(REDIS_URL)
# retrieve info about the function to run and args to use
task_info = json.loads(redis_client.get(REDIS_TASK_INFO_KEY))
module_name = task_info["module"]
fn_name = task_info["function_name"]
args = task_info.get("args", [])
kwargs = task_info.get("kwargs", {})
module = importlib.import_module(module_name)
task_fn = getattr(module, fn_name)
# do the actual work
result = task_fn(*args, **kwargs)
# write results to Redis
redis_client.set(REDIS_RESULTS_KEY, json.dumps({
"status": "SUCCESS",
"result": result
})
if __name__ == '__main__':
run_task()
You might notice something missing here — the code that actually sends the email. You’ll also need to implement the functions that do the work of the background jobs, and include them in the worker library. You can take a look at the send_email function in tasks.py in the demo code repo, to see the implementation for sending an email!
Here’s an example of the task info that might be stored in Redis for sending an email from our demo app:
{
"module": "tasks",
"function_name": "send_email",
"args": [
"your-friend@yourfriendsdomain.com",
"Hello from my Fly.io app!",
"Hello friend! I sent this email from my app on Fly.io!"
],
"kwargs": {
"to_name": "Friend's Name",
"from_email": "you@yourdomain.com"
}
}
We’re sending the module and function name as strings in the task information in Redis. There are more sophisticated options here, but this approach works for our simple use case!
Code to call the worker
Then, let’s take a look at the code that we’ll use to set up the Machine and kick off the background job:
headers = {
"Authorization": f"Bearer {FLY_API_TOKEN}",
"Content-Type": "application/json"
}
def run_task(module_name, function_name, args=None, kwargs=None):
redis_client = redis.from_url(REDIS_URL, decode_responses=True)
args = args or []
kwargs = kwargs or {}
task_id = f"{function_name}-{uuid.uuid4()}"
redis_task_info_key = f"{TASKS_KEY_PREFIX}{task_id}"
redis_results_key = f"{RESULTS_KEY_PREFIX}{task_id}"
machine_config = {
"name": task_id,
"config": {
"image": WORKER_IMAGE,
"env": {
"REDIS_TASK_INFO_KEY": redis_task_info_key,
"REDIS_RESULTS_KEY": redis_results_key
},
"processes": [{
"name": "worker",
"entrypoint": ["python"],
"cmd": ["worker.py"]
}]
}
}
redis_client.set(redis_task_info_key, json.dumps({
"module": module_name,
"function_name": function_name,
"kwargs": kwargs,
"args": args
}))
response = requests.post(
f"https://api.machines.dev/v1/apps/{FLY_TASKS_APP}/machines", headers=headers, json=machine_config
)
response.raise_for_status()
# store the machine id so we can use it later to check if the job has completed
machine_id = response.json()["id"]
redis_client.set(f"{MACHINE_INFO_KEY_PREFIX}{task_id}", machine_id)
return {
"task_id": task_id
}
We’ll call this code from our web application whenever the POST endpoint (to send an email) is called. This will kick off the job running on a Fly Machine, and return the task id, which is used to retrieve the results!
Code to retrieve results
When we retrieve the results, we need to first check whether the Machine is still running. If it’s still running, we can just return a PENDING status, and expect the client will try again later.
Once the Machine is done, we can retrieve the result that the job wrote to Redis, and return it to the caller!
def get_results(task_id):
redis_client = redis.from_url(REDIS_URL, decode_responses=True)
# check whether the machine is still running
machine_id = redis_client.get(f"{MACHINE_INFO_KEY_PREFIX}{task_id}")
response = requests.get(
f"https://api.machines.dev/"
f"v1/apps/{FLY_TASKS_APP}/machines/{machine_id}",
headers=headers
)
machine_info = response.json()
if machine_info["state"] in ("starting", "created", "started"):
return {
"status": "PENDING"
}
# if the machine is done, get the result!
result = redis_client.get(f"{RESULTS_KEY_PREFIX}{task_id}")
return json.loads(result)
In our simple demo web application, we have a GET /status/{task_id} endpoint, which calls this function to retrieve the result and then displays it to the user. If the status is PENDING, the user can refresh the page to try again.
Code to clean up resources
After results have been retrieved, you’ll want to clean up: remove the Machine, and delete the values stored in Redis.
def clean_up(task_id):
redis_client = redis.from_url(REDIS_URL, decode_responses=True)
machine_id = redis_client.get(f"{MACHINE_INFO_KEY_PREFIX}{task_id}")
requests.delete(
f"https://api.machines.dev/"
f"v1/apps/{FLY_TASKS_APP}/machines/{machine_id}",
headers=headers
)
redis_client.delete(f"{TASKS_KEY_PREFIX}{task_id}")
redis_client.delete(f"{RESULTS_KEY_PREFIX}{task_id}")
redis_client.delete(f"{MACHINE_INFO_KEY_PREFIX}{task_id}")
And that’s it! Now we have a super-simple implementation of background jobs using Fly Machines. 🎉
What’s next?
In this post, I’ve presented a very simple proof of concept implementation of background jobs on Fly.io Machines with Python. For some simple apps, you can use this approach as it is, but there’s a lot more you could do without very much effort! Here’s some ideas to get you started:
- Write a generic Python library for this purpose, which could be reused across different apps.
- Right now there’s a limitation: job request args and results need to be JSON-serializable. This is fine for many use cases, but it could be interesting to explore other alternatives!
- My implementation uses a separate Docker image for the worker, but you could also use the same image as the web app, similarly to what Brad did in his Ruby background jobs on Machines implementation.
- Instead of a library, you could create a language-agnostic service. Using Fly Machines scale-to-zero capability, this service could avoid incurring unnecessary costs for idle time.