
We’re Fly.io. We run apps for our users on hardware we host around the world. Fly.io happens to be a great place to run Phoenix applications. Check out how to get started!
I created an Elixir LangChain library called “langchain” on Hex.pm. I didn’t invent the idea of LangChain. In fact, it was originally created in Python and JS/TS. I wanted something similar to exist for Elixir and Phoenix applications.
What is LangChain?
Wikipedia sums it up well:
LangChain is a framework designed to simplify the creation of applications using large language models (LLMs).

In short, the Elixir LangChain framework:
- makes it easier for an Elixir application to use, leverage, or integrate with an LLM
- abstracts away differences between various LLMs
- removes boilerplate
- provides tools to automate common and even complex tasks
Which LLMs does it support?
With the initial release (v0.1.0), only ChatGPT is supported. The library is built in a way that adding more LLMs can hopefully be done with minimal or no changes needed to an application.
Expect more LLMs to be supported in the future. Here’s the short list:
- Meta’s Llama 2
- Google’s Bard
Impatient? Get involved! 🙂
Who is this for?
If you want to use Elixir to play with ChatGPT or other LLMs, then this is for you!
What kinds of things can I do with it?
Out of the box you can:
- have a conversation with an LLM (more on this up next)
- stream the results back
- use templates to build prompts (ie LangChain.PromptTemplate)
- build complex, multi-level prompts (ie LangChain.PromptTemplate.format_composed/3)
- use an LLM to extract structured data from text (ie LangChain.Chains.DataExtractionChain)
- integrate the LLM into your Elixir application using a LangChain.Function
- define your own tools to expose to the LLM like the included LangChain.Tools.Calculator
There’s more to talk about with each of these which we can hopefully cover that in future posts.
The point is, this is a solid foundation that can already do quite a bit. If you compare this to the more established JS LangChain, you’ll realize there’s a lot more this library could do. But hey, this is just getting started!
I should also make it clear that I’m not trying to match the JS LangChain library feature for feature. I’d like to see some things they don’t do and they include things I think are a terrible idea. 😄
Getting Started
Here’s the basic “hello world” example. After making your OpenAI API key available to the library, the code looks like this:
alias LangChain.Chains.LLMChain
alias LangChain.ChatModels.ChatOpenAI
alias LangChain.Message
{:ok, _updated_chain, response} =
%{llm: ChatOpenAI.new!(%{model: "gpt-4"})}
|> LLMChain.new!()
|> LLMChain.add_message(Message.new_user!("Hello world"))
|> LLMChain.run()
response.content
#=> "Hello! How can I assist you today?"
Here’s what’s happening in the above example:
- We set up the LLM we want to use. In this case, it’s the ChatGPT model from OpenAI. We specify that we want to use the “gpt-4” version of the model.
- We start a new chain. A “chain” is the heart of the library. It connects a number of different things together and provides a lot of conveniences.
- Next we create and add a new
usermessage to the chain. This is our request. - Finally we
runthe chain, which sends the conversation to ChatGPT. ChatGPT generates a response which receive back in a newresponsemessage.
If we held on to the updated_chain returned from the run function, we’d have a new LLMChain with a new message added from the assistant.
Conversational LLMs are built on the idea of “messages”. A chain or sequence of messages makes a “conversation”. We use a LangChain.Message struct to model this for us.
Stateless Conversations?
Normal HTTP requests are stateless, right? We rebuild the state of the world with every request. Conversational LLMs are the same way! They are stateless! 🤯
If you’ve ever played with ChatGPT, then it’s really fun when you realize you can write something that refers to a previous part of the conversation and magically it works and knows what you’re talking about!
The reason this works is because every time we add a new message or want to continue the conversation and say something else, we pass along the entire conversation up to this point with our addition tacked on at the end.
Here’s a visual example of the different message types in a typical conversation.
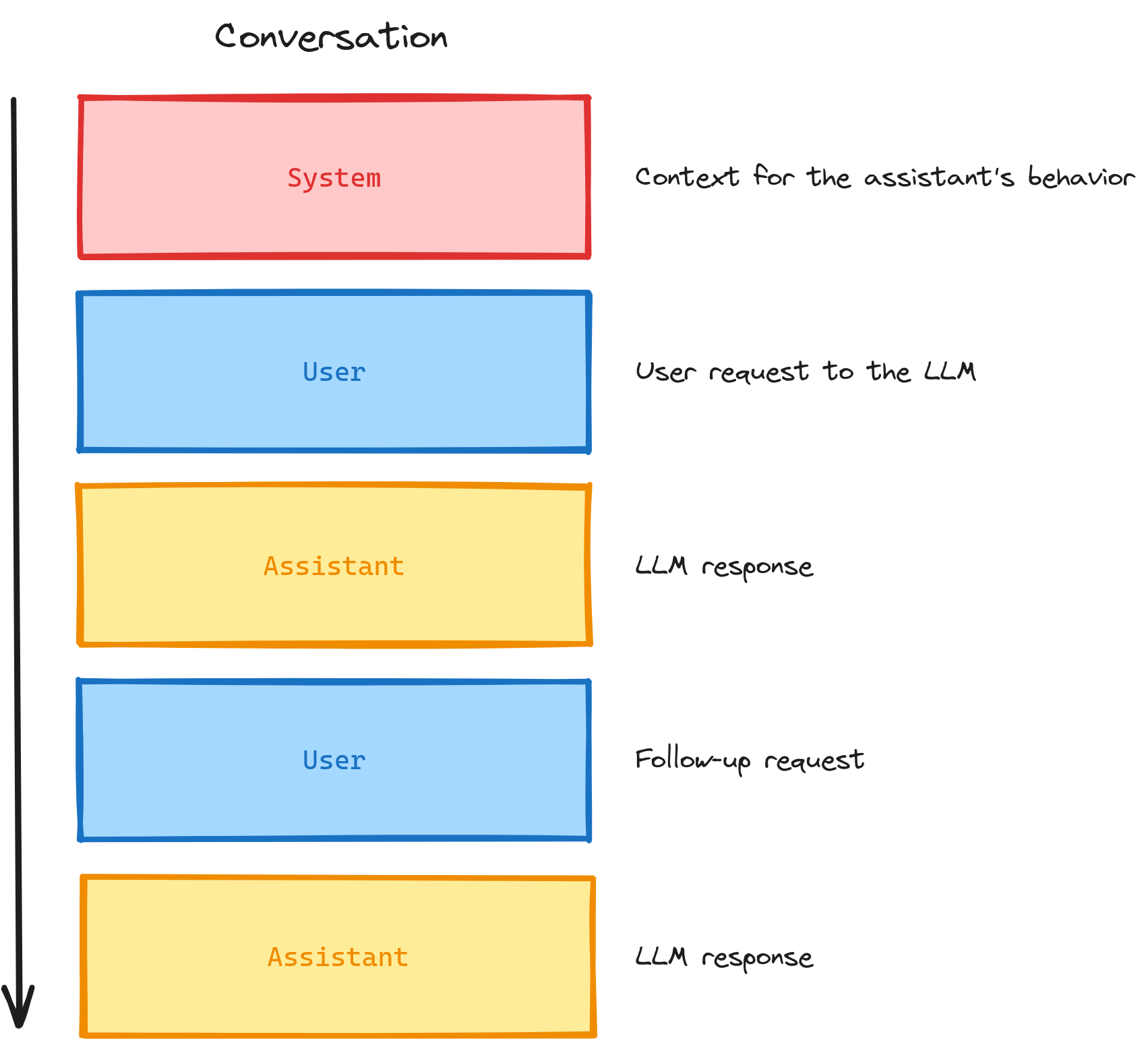
Because of this stateless nature, if we store a conversation and pull it up a week later, we can add a message, submit it, and the LLM treats it like there was no pause or delay!
The LLMChain module helps manage the conversation for us. And yes, it makes it easy to stream the results back and apply them to the conversation too. 😁
Where to Start?
For those who have used Livebook before, check out the project’s Livebook notebooks with functional examples.
Otherwise, the project’s installation section should get people going.
The online documentation also includes numerous examples.
Until next time, happy hacking! 👋
Fly.io ❤️ Elixir
Fly.io is a great way to run your Phoenix LiveView apps. It’s really easy to get started. You can be running in minutes.
Deploy a Phoenix app today! →