

This dev blog digs deeper into fixing an 8-year old bug. We learn more about the internals of Phoenix and LiveView in the process. Fly.io is a great place to run a Phoenix application! Check out how to get started!
I’ve had my fair share of bug reports over the ~10 year life of maintaining Phoenix. Most are mundane Elixir tweaks, or wrangling some JavaScript issues. The core of Phoenix has been baked for years now, so color me surprised when I found myself spelunking through code about as old as Phoenix itself trying to make sense of what I was seeing.
The bug report
What’s interesting about this report is that it almost went unaddressed. It could have been another 10 years before I poked at it. I caught a passing comment on the Phoenix slack about an obscure problem. The user hadn’t yet filed a GitHub issue, so if I had missed this comment, it may have been lost in the ether.
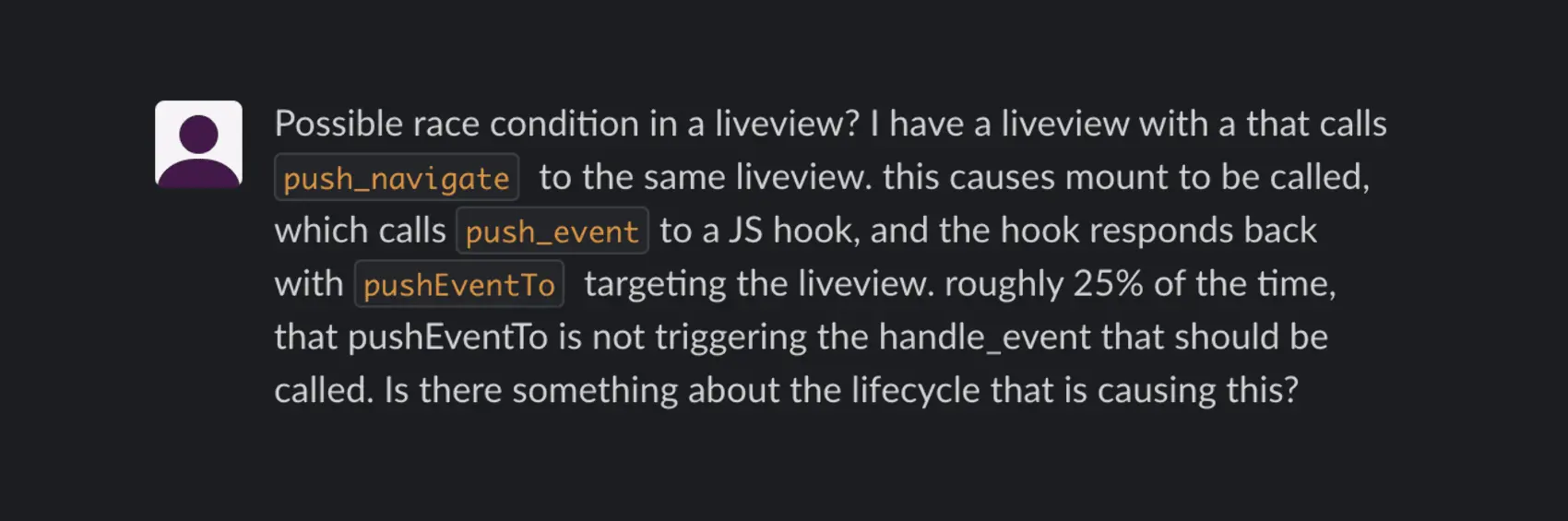
This description makes it sound like a somewhat “obscure” issue, in that there are a couple features being used together, JavaScript Hooks and Live Navigation, at a specific point in the LiveView lifecycle. So when I read this, I thought it was a potential bug, but sure to be infrequently hit in the wild.
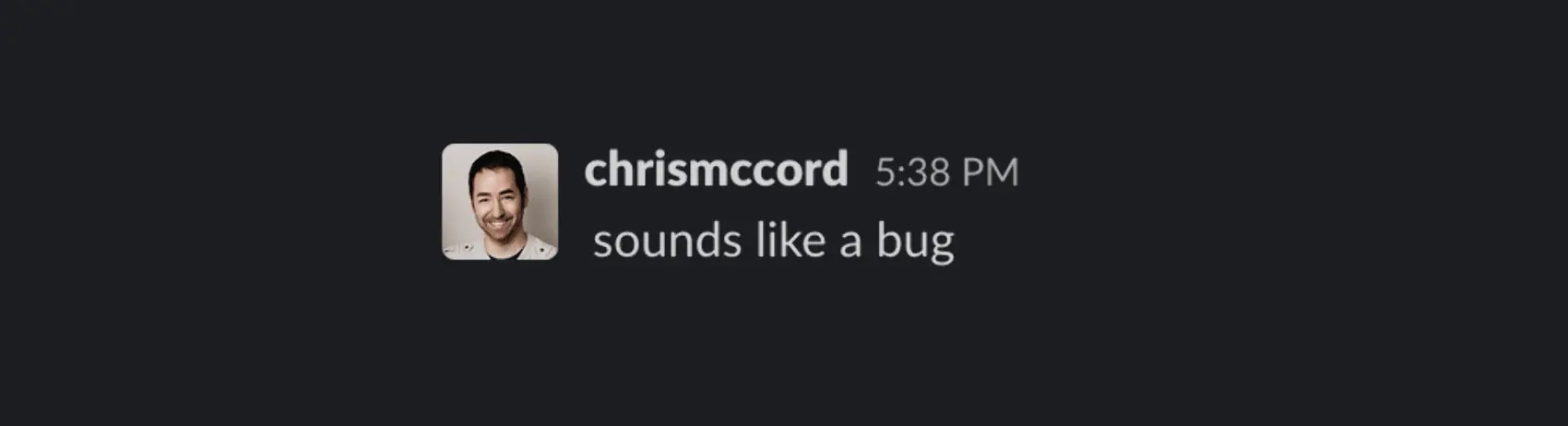
Narrator: Yes Chris, it was indeed a bug.
The user followed up with more info:
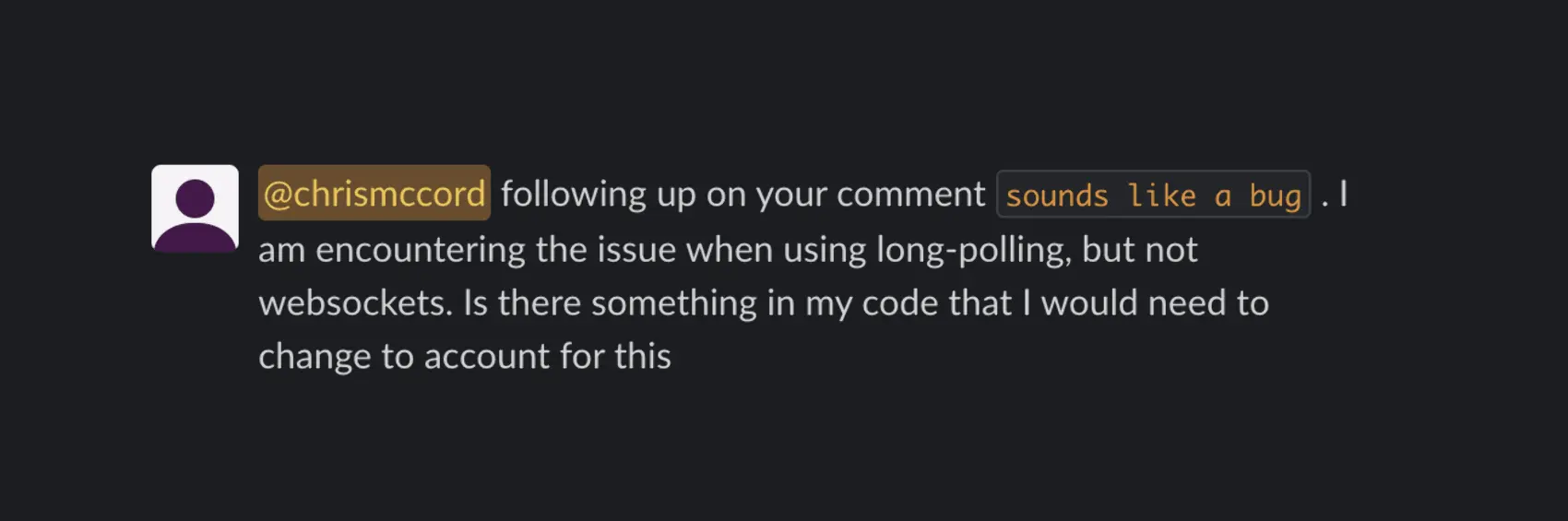
Great. So it happens only with long polling, and only when using JavaScript Hooks with Live navigation, and only during the LiveView mount. Nothing to get too worked up about, right?!
Wrong.
In about five minutes I had recreated the issue where the application would break, but to my dismay it was much worse than reported. What sounded like an obscure race of JavaScript Hooks pushing and receiving events to a LiveView doing live navigation sent me down a four hour rabbit hole.
To try to isolate the issue, I commented out my JavaScript hook, and simply let the app do a push_navigate in the LiveView when a button was clicked.
The client completely broke, about 25% of the time. This is bad.
Live Navigation explained
To understand why this is bad, let me explain a bit about what “Live Navigation” is and what the call to push_navigate is. Phoenix LiveView works by rendering the UI on the server and diffing changes back to the browser. We have an abstraction for navigating from page to page without requiring a full browser reload. We do this by issuing a page navigation over the existing transport, such as a WebSocket frame, or a Long-poll message. This has the benefit of avoiding extra HTTP handshakes for WebSockets, and avoiding full page loading and parsing in the case of long-polling.
So rather than doing a redirect(socket, to: "/path") a user may push_navigate(socket, to: "/path"), and the browser updates and loads the page, but with a nice performance boost. This is a fundamental features of LiveView and one you should use whenever you can.
So how was this fundamental feature breaking so easily, and how was this not yet reported? Also, how in the world was this a bug. We hadn’t touched long-poll code in probably 8 years on the client or server.
Lay of the land
To understand the bug, we need to understand a little bit of how LiveView and Phoenix channels works. Phoenix LiveView is built on top of Phoenix channels, which is an abstraction for bidirectional client/server messaging. We get the same interface whether you’re running over WebSockets (the default), or long-polling, or any other custom channel transport that speaks the channel protocol. The interface looks like this:
let mainChatChannel = socket.channel("room:1")
mainChatChannel.join()
.receive("ok", ({welcome}) => alert(`joined! ${welcome}`))
.receive("error", ({reason}) => alert(`error: ${reason}`))
mainChatChannel.on("new_msg", ({body}) => alert(`room:1: ${body}`)
let privateChatChannel = socket.channel("private:123")
privateChatChannel.join()
.receive("ok", ({welcome}) => alert(`joined! ${welcome}`))
.receive("error", ({reason}) => alert(`error: ${reason}`))
privateChatChannel.on("new_msg", ({body}) => alert(`private: ${body}`)
One neat thing about channels is they are multiplexed. This means we can open any number of channels on a single physical connection. Channels are identified by a topic, which is a unique string, such as "room:1" or "private:123" above which allows these isolated “channels” of communication across a single wire.
For LiveView, when you connect to the server, we open a channel for each LiveView in the UI. The LiveViews representing each part of the UI each get their own channel. This is nice because each channel process on the server runs concurrently. Blocking work in one channel won’t block work in another, even for the same browser user.
So we have multiplexed channels and each channel joins a topic. LiveViews are channels underneath, and so they also use a topic. LiveView topics are randomly generated.
The LiveView topic is signed into a token when first rendering the page over the regular HTTP request. We affectionately call this the “dead render” or “dead mount”. On the dead render, we place the token into the page. Then the LiveView connects over channels for the live render, lifts the token from the HTML document, and joins the channel with the topic we signed in the token.
We use the token to verify that the channel topic the client is trying to join is indeed the one we leased to them. Within this token is the LiveView module name, router, and other metadata of the code paths we’ll invoke when the user performs a live mount.
When you perform live navigation like push_navigate the client will reuse the channel topic for the new LiveView.
Hang with me. We’re almost there where we’ll be able to WTF together about the bug.
Reusing Channel Topics
So the LiveViews have topics they join, and they are randomly generated and verified on the server. So why are they re-used for push_navigate? Why not generate a new one? Remember, the token we signed from the dead mount contains the topic. Our whole goal is to avoid making new HTTP requests to fetch a whole new page. We want to take advantage of the existing channel connection. This means re-using the signed token, and thus re-using the channel topic for the “old” LiveView we are navigating away from. The LiveView client conceptually does the following on live navigation:
this.mainLVChannel.leave()
this.mainLVChannel = socket.channel(this.mainLVChannel.topic, {token, url: newURL}))
this.mainLVChannel.join()
.receive("ok", (diff) => {
Browser.pushState(newURL)
render(diff))
})
To perform live navigation, the client leaves the current LiveView channel and joins a new channel with the same topic. It passes its token from the original HTML document, and the new URL that it wishes to navigate to. On the server, LiveView verifies that the route for the newURL is allowed to be accessed from the old LiveView/URL, and it starts the new channel process. The browser gets the diff on the wire, and updates the URL in the address bar via push state.
Duplicate Topics
At this point, the final piece to understand about channels is the way topics are handled in the transport. Since channels are multiplexed, a topic must be unique on the physical connection. If you try run the following client code:
let chan1 = socket.channel("room:123")
chan1.join()
let chan2 = socket.channel("room:123")
chan2.join()
The server will close chan1, and start a new process for chan2. Each channel instance also carries a unique join_ref , which is essentially a unique session ID . This is important because it allows the server and client to avoid sending latent messages for a given topic to a newer instance on the client, if for example we raced a phx_close event from the server or vice versa.
So if the Phoenix transport layer handles duplicate topics already, why are we having a bug with push_navigate re-using topics? And why only with the long-poll transport?
Diagnosing the bug
The bug is experienced in the application as the UI becoming unresponsive. The socket connection remains up, but when a user clicks a navigation link, everything just… stops.
Here’s the flow of events that I pieced together, when viewed from the client:
1. User visits page LiveView page A
2. User clicks a link that does push_navigate to LiveView page B
3. client longpoll: send phx_leave page A
4. client longpoll: send phx_join page B
5. client longpoll: receive ack for # 3 phx_leave
6. client longpoll: receive ack for # 4 phx_join
7. client longpoll: receive phx_close page B (normal close)
Everything in the logs makes sense until #7. When the user clicks a navigation link, the client sends the correct order of messages. A leave event for the current channel, a join to the new channel, and acknowledgments for each. The new LiveView channel is joined properly, but then it immediately closes with a normal closure from the server.
WTF.
Remember, the Phoenix server handles back-to-back re-use of channel topics just fine. The long-poll client sends the phx_leave before the new phx_join as well, so how in the world are we closing down the new channel?
I spent about hour or so of WTF'ery trawling through Phoenix long-poll and transport layer source that I hadn’t seen in years. I then called @peregrine , a phoenix-core member and fellow Fly'er. We spelunked through the server code for a couple more hours and pieced together the following flow of events when viewed from the server:
1. mount LiveView page A
2. push_navigate to LiveView page B
3. server longpoll: receive phx_join page B
4. server longpoll: receive phx_leave page A
25% of the time we are receiving the phx_leave after the phx_join, even though the client sent the HTTP requests as phx_leave, phx_join. So the client sends the correct order, but the server processes them out of order.
I realize at some point that the entire architecture of long-polling is inherently race condition prone. The long-poll transport that has existed for 10 years is fundamentally flawed. Great. But why?
The way long-polling works to simulate a bidirectional pipe by POST'ing events to the server for channel.push(), and GET'ing events from the server for channel.on by repeatedly polling the server and hanging the connection awaiting events. Hanging the connection waiting for events is the “long” in long-polling,
Meanwhile a process sits on the server and buffers events in between the client going down for each new poll request. This works great, but therein lies the flaw.
Since long-poll issues separate HTTP requests for pushed events, those HTTP requests are handled concurrently by the server. Either on the same server in different TCP acceptors from the connection pool, or by different servers entirely due to load balancing. The long-poll transport handles proxying the messages back to the original server in the load-balancing case, but a race condition exists here even for single-server use.
Because the HTTP requests are processed concurrently and relayed to the long-poll process, there is no guarantee they will arrive in order.
This is bad.
It explains our bug where the server sees the phx_join, then the phx_leave. Fortunately, we already have a join_ref which uniquely tracks each channel, so we can detect this situation and prevent the latent close from killing the new channel.
This is the patch in the channel transport layer that resolved the original bug report:
defp handle_in({pid, _ref, _status}, %{event: "phx_leave"} = msg, state, socket) do
%{topic: topic, join_ref: join_ref} = msg
case state.channels_inverse do
# we need to match on nil to handle v1 protocol
%{^pid => {^topic, existing_join_ref}} when existing_join_ref in [join_ref, nil] ->
send(pid, msg)
{:ok, {update_channel_status(state, pid, topic, :leaving), socket}}
# client has raced a server close. No need to reply since we already closed
%{^pid => {^topic, _old_join_ref}} ->
{:ok, {state, socket}}
end
end
I added a handle_in clause for handling incoming messages which looks for phx_leave events. If we receive a phx_leave with a join_ref matching the currently tracked channel, we process it as normal and leave the channel. If we find a mismatched join_ref, it is necessarily from a latent close and we noop. This is also nice because an incorrectly coded client could issue a latent leave.
This fixed the bug report. But we can’t celebrate too much yet.
Fixing the fundamental long-poll flaw
Fixing the latent leave issue still leaves us with long-poll backed channels that have no message ordering guarantees. This is bad. The following code could not be trusted to deliver messages in order:
let chatChannel = socket.channel("rooms:123")
chatChannel.push("new_msg", {body: "this is my first message!"})
chatChannel.push("new_msg", {body: "this is my second message!"})
The code resulted in the following timing issue:
- Two POST requests are sent (in order from the client perspective).
- We can’t count on receiving them in that order.
- Depending on which TCP acceptor picked up the request and which core/scheduler processed the request first, the second message could arrive before the first.
- Ditto if you load balance to a completely different server for one of the requests and we have to bounce the message back to you over distributed Elixir.
The original bug report could be fixed only with server changes. Fixing this fundamental race condition requires client-side changes. And there are tradeoffs to make this right.
Fundamentally we must guarantee channel push ordering from client to server. The easiest solution would be to make channel pushes synchronous. Internally we’d queue all pushes and await an acknowledgment before sending the next one. This would guarantee order, even if you load balance to different servers each time.
It would also be super slow.
The great thing about WebSockets is we perform the HTTP/TLS handshake a single time and then we get our bidirectional pipe that lets us spam messages one after another – order is preserved. With long-polling, we emulated this, but having to serialize each individual channel.push would require a full round trip one-by-one. It would also mostly eliminate the benefit of live navigation because we’d have to make two round trips to navigate between pages. One to leave the current channel, and one to join the new one. This is a nonstarter.
Still, we need a solution, and it needs to be correct.
Where we landed is a client-side queue that batches requests. This way we strike a balance between synchronous messages and the full fire-and-forget of WebSockets.
When push is invoked, we first check to see if we are awaiting an acknowledgement from a previous batch. If not, we can issue the POST, otherwise we queue it up to be sent as soon as the acknowledgement arrives.
This is great, but it still suffered the 2x round trip for live navigation because a back-to-back phx_leave + phx_join on an empty queue would immediately send the leave, and wait a full round trip to send the join. This is not any better for the live navigation case that with an empty queue.
I fixed this with a little trick. We know we have to batch, but what we really care about is optimizing the case where you have some procedural code in the same event loop like our chat messages above, or the LiveView navigation.
If we are pushing with no current batch, we can schedule the batch to run on the next tick of the JavaScript event loop via a setTimeout(() => .., 0). This allows us to catch pushes that happen in the same event loop as the first push. When the next tick fires “0” milliseconds later, we’ll have our back-to-back pushes queued up and sent together in one batch. Here’s the notable snippets from my patch tophoenix.js and the LongPoll transport where I used this approach:
longpoll.js:
send(body){
- this.ajax("POST", body, () => this.onerror("timeout"), resp => {
+ if(this.currentBatch){
+ this.currentBatch.push(body)
+ } else if(this.awaitingBatchAck){
+ this.batchBuffer.push(body)
+ } else {
+ this.currentBatch = [body]
+ this.currentBatchTimer = setTimeout(() => {
+ this.batchSend(this.currentBatch)
+ this.currentBatch = null
+ }, 0)
+ }
}
+ batchSend(messages){
+ this.awaitingBatchAck = true
+ this.ajax("POST", "application/ndjson", messages.join("\n"), () => this.onerror("timeout"), resp => {
+ this.awaitingBatchAck = false
if(!resp || resp.status !== 200){
this.onerror(resp && resp.status)
this.closeAndRetry(1011, "internal server error", false)
+ } else if(this.batchBuffer.length > 0){
+ this.batchSend(this.batchBuffer)
+ this.batchBuffer = []
}
})
}
longpoll.ex:
Puzzled by application/ndjson? That’s to process ndjson formatted JSON. It’s just regular JSON that uses newlines to delimit values.
defp publish(conn, server_ref, endpoint, opts) do
case read_body(conn, []) do
{:ok, body, conn} ->
- status = transport_dispatch(endpoint, server_ref, body, opts)
+ # we need to match on both v1 and v2 & wrap for backwards compat
+ batch =
+ case get_req_header(conn, "content-type") do
+ ["application/ndjson"] -> String.split(body, ["\n", "\r\n"])
+ _ -> [body]
+ end
+ {conn, status} =
+ Enum.reduce_while(batch, {conn, nil}, fn msg, {conn, _status} ->
+ case transport_dispatch(endpoint, server_ref, msg, opts) do
+ :ok -> {:cont, {conn, :ok}}
+ :request_timeout = timeout -> {:halt, {conn, timeout}}
+ end
+ end)
conn |> put_status(status) |> status_json()
_ ->
raise Plug.BadRequestError
end
end
The good news is took a remarkably small amount of code on the client and server to resolve these fundamental issues. Ordering is now guaranteed, and long-polling is still able to be reasonably performant when pushing messages. The bad news was it cost a couple days of work after all was said and done.
Why it took 10 years for someone to report this
It seems like such a fundamental design flaw would have been reported by now, right? I think there’s a couple reasons for this.
First, the “app is completely broken” failure mode only happened when you have a duplicate topic do a back-to-back channel leave and join. LiveView does this, but it’s not a typical pattern for most regular Phoenix channel applications, where each channel instance will be associated to a unique topic – think each slack DM having its own topic. LiveView has been out for a few years, but the six years prior saw most channels applications simply never use this kind of pattern.
Second, it only affected the long-poll transport, which ships with Phoenix, but is not enabled by default. The vast majority of folks aren’t running long-poll today because it’s a knob they only turn when they need it.
I’m super happy I was able to connect with the passing issue on Slack and get this fix in place. While I was tending to this “ancient” Phoenix code path, I also took the opportunity to bake in some new long-poll enhancements, which will be the topic for another post.
Happy hacking,
–Chris
Fly.io ❤️ Elixir
Fly.io is a great way to run your Phoenix LiveView app close to your users. It’s really easy to get started. You can be running in minutes.
Deploy a Phoenix app today! →